The INSPIRE Data Hub is a FAIR data resource containing longitudinal population health data from Health and Demographic Surveillance System (HDSS) sites in southern and eastern Africa. It is designed with the idea that population health data can be usefully combined with data from other sources, notably routine healthcare data from clinics. It is designed to be both scalable and extensible, based on international standards, allowing for additional data in new areas to be introduced without requiring a new hub infrastructure.
By working with ODHSI’s OMOP Common Data Model, and integrating population data, a host of different alignments and integrations are becoming available, now and into the future, to ultimately include genomics data, clinical trials, and administrative data. INSPIRE will benefit from this work, as part of a broader, global data-sharing infrastructure for health research.
The long-term goal is to provide a robust pan-African platform for data integration. The hub is designed to coordinate with other African initiatives such as the national network service providers (NRENs) and the African Open Science Platform (AOSP). The INSPIRE Data Hub is being developed by a network of HDSS sites and interested organizations which can provide the needed governance for the platform.
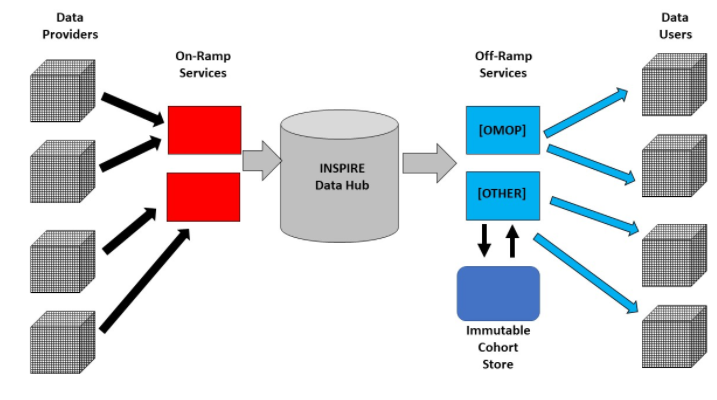
The diagram below shows the basic conceptual components of the INSPIRE Hub architecture:
Several documents provide a greater level of detail about the results of Phase I of the project, which has focused on design/architecture and prototyping. These are described below, in reference to the following schematic:
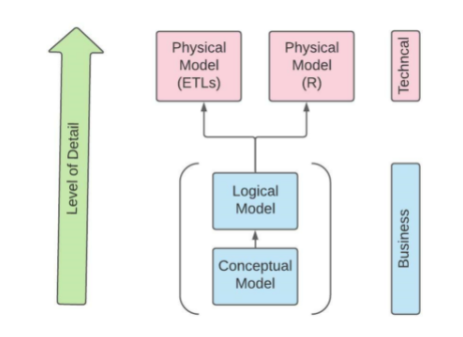
The documents described below cover different aspects of the Phase I technical work.
INSPIRE Data Hub: High-Level Architecture and Data and Metadata Flows
This document provides a conceptual and logical overview of the INSPIRE Data Hub architecture. It covers the basic interaction of system components as shown in the diagram above and addresses the flow of documentation and metadata to users, the packaging of data for non-ODHSI client “off-ramps,” citation and archiving, user management, access control, and management functions. (This is at the Business level in the schematic above).
This document describes the specific extraction, transformation, and load (ETL) process needed to support the “on-ramp” service for HIV data supplied by the ALPHA Network. This was the prototype use case for exploring the ETL functions at the Technical level. The OMOP CDM relies on agreed database table structures and standard vocabularies, and mapping data sources against these is a core feature of data sharing in the OHDSI framework. The integration of population data required some extensions of these vocabularies. This work is described here.
OHDSI and the I-ADOPT Interoperability Framework
This paper details the use of the I-ADOPT Interoperability Framework as it relates to the OHDSI OMOP Common Data Model (CDM) and looks forward to an issue which will be further explored in INSPIRE PEACH. The paper offers an analysis of the benefits of using a lightweight conceptual model such as I-ADOPT, which can simultaneously capture the local data source and the target topic variable. The I-ADOPT framework provides a structured, machine-readable way of expressing the relationships between a variable and its qualifiers. OMOP does not have these same structural capabilities. In this way, the I-ADOPT framework acts as a bridge of sorts which contains both human- and machine-readable components which are documented for each variable. This forms the basis of ETLs and can be leveraged by human implementers programmatically. (This is a document which spans the Logical and Technical levels in the schematic above.)
INSPIRE EA IT Infrastructure on the Cloud
This document describes the implementation of an OMOP CDM-compliant database in the Cloud, from the perspective of Africa-based INSPIRE Data Hub. It examines the issues of establishing and managing this type of data store at a practical level (this is at the Technical level in the schematic above). This was an exploratory effort, conducted as a prototype – it is expected that a production implementation would be hosted by established infrastructure networks (e.g., UbuntuNet, African Open Science Cloud, etc.)