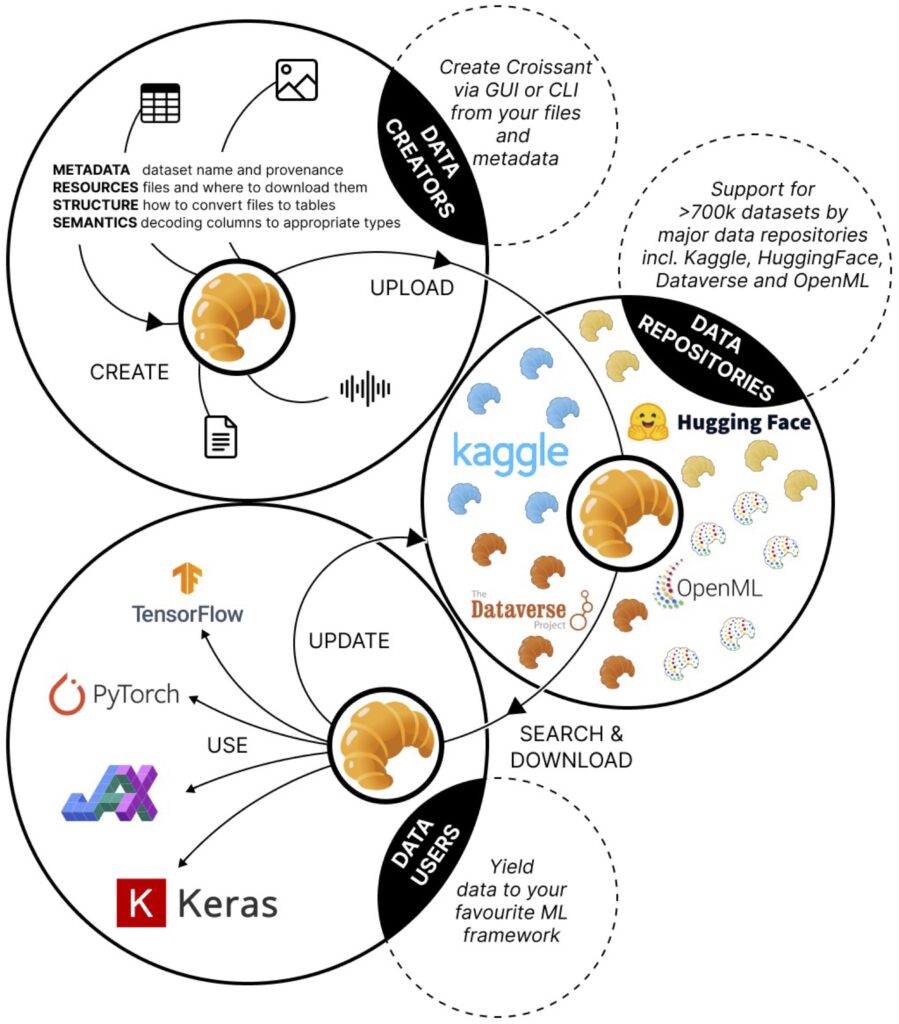
 There is currently a lot of interest in how we maximise increase the effectiveness of datasets for AI training and fine-tuning through metadata. This led to the development of the ML Croissant metadata specification, “an open community-built standardized metadata vocabulary for ML datasets, including key attributes and properties of datasets, as well as information required to load these datasets in ML tools. Croissant enables data interoperability between ML frameworks and beyond, which makes ML work easier to reproduce and replicate.”
There is currently a lot of interest in how we maximise increase the effectiveness of datasets for AI training and fine-tuning through metadata. This led to the development of the ML Croissant metadata specification, “an open community-built standardized metadata vocabulary for ML datasets, including key attributes and properties of datasets, as well as information required to load these datasets in ML tools. Croissant enables data interoperability between ML frameworks and beyond, which makes ML work easier to reproduce and replicate.”
In turn, there is also great potential for AI tools to enhance metadata and to assist in establishing semantic mappings. A session at IDW recently explored these issues: ‘AI for Metadata Enhancement, Metadata for AI Readiness: how do we ensure a virtuous rather than a vicious circle?’ In this session, and in a plenary session on AI for Science, Slava Tykhonov, Head of Interoperability and AI at CODATA presented his work on Semantic Croissant, an extension of ML Croissant that is powered by the CODATA Cross-Domain Interoperability Framework (CDIF). This knowledge graph, maintained at the variable level, is designed to guide and navigate AI through structured expert knowledge. The crucially important step is to incorporate CDIF’s use of the DDI-CDI variable description providing a rich ![]() semantic description of the core feature of the dataset: the observable property that was measured or described. This has benefits for interoperability and reuse of data and for its effectiveness in the training of AI models. It also helps situate the variable description as a first-class semantic object, which is one of the key purposes of CDIF. Slava’s presentation can be viewed on DataverseTV.
semantic description of the core feature of the dataset: the observable property that was measured or described. This has benefits for interoperability and reuse of data and for its effectiveness in the training of AI models. It also helps situate the variable description as a first-class semantic object, which is one of the key purposes of CDIF. Slava’s presentation can be viewed on DataverseTV.
There is considerable interest in this work. Slava has been invited to give a keynote to the NFDI4DataScience Conference, taking place on 25–26 November 2025 at Fraunhofer FOKUS in Berlin. The NFDI4DS initiative aims to build and sustain a national research data infrastructure for the Data Science and Artificial Intelligence community in Germany – an exciting step toward more interoperable, transparent, responsible and FAIR AI.
 Slava has also been invited to speak at as CESSDA AI Workshop, as part of the 4-day “CESSDA at 50” conference in Bergen, 15-18 June 2026. This 50th-anniversary event will bring together CESSDA Service Providers, researchers, policy actors, partner organisations, and international networks to share knowledge and address the evolving landscape of research and innovation.
Slava has also been invited to speak at as CESSDA AI Workshop, as part of the 4-day “CESSDA at 50” conference in Bergen, 15-18 June 2026. This 50th-anniversary event will bring together CESSDA Service Providers, researchers, policy actors, partner organisations, and international networks to share knowledge and address the evolving landscape of research and innovation.