 This is the fifteen in the series of short statements from candidates in the forthcoming CODATA Elections at the General Assembly to be held on 9-10 November in Gaborone, Botswana, following International Data Week. Tony Hey is a candidate for the CODATA Executive Committee as CODATA President. He was nominated by UK.
This is the fifteen in the series of short statements from candidates in the forthcoming CODATA Elections at the General Assembly to be held on 9-10 November in Gaborone, Botswana, following International Data Week. Tony Hey is a candidate for the CODATA Executive Committee as CODATA President. He was nominated by UK.
CODATA’s Mission
“CODATA exists to promote global collaboration to advance Open Science and to improve the availability and usability of data for all areas of research. CODATA supports the principle that data produced by research and susceptible to be used for research should be as open as possible and as closed as necessary. CODATA works also to advance the interoperability and the usability of such data: research data should be FAIR (Findable, Accessible, Interoperable and Reusable). By promoting the policy, technological and cultural changes that are essential to promote Open Science, CODATA helps advance ISC’s vision and mission of advancing science as a global public good” [1]
Preface
In my present position as the Chief Data Scientist of the UK’s Science and Technology Facilities Council (STFC), I am based at the Rutherford Appleton Laboratory (RAL), on the Harwell Campus near Oxford. The Harwell site hosts the Diamond Synchrotron, the ISIS Neutron Source and the UK’s Central Laser Facility. My primary role is to support the university users of these large-scale experimental facilities at RAL in managing and analyzing their research data. The users of these facilities now perform experiments that generate increasingly large and complex datasets which need to be curated, analyzed, visualized and archived, and their new scientific discoveries published in a manner consistent with the FAIR principles. In addition, I work with the Hartree Supercomputing Centre at the STFC’s Daresbury Lab near Manchester. The Hartree Centre works mainly with industry and supports their computer modelling and data science requirements.
I am therefore intimately acquainted with the challenges of open science and believe, thanks in part to the activities of CODATA, together with its fellow ISC organization, the World Data System (WDS) and now also with their younger partner, the Research Data Alliance (RDA), that the global scientific research community has made significant progress towards the goals of the CODATA mission over the last five years. However, there is still much more to do before we can realize anything close to the Jim Gray’s vision of the full text of all publications online and accessible, linked to the original datasets with sufficient metadata that other researchers can reuse and add new data to generate new scientific discoveries. In his last talk before he went missing at sea, he summed up this vision in the ‘pyramid’ diagram below [2]:

The European Open Science Cloud (EOSC) has a similar vision but is aiming to provide a much more detailed roadmap towards realizing a vision of global research that is Findable, Accessible, Interoperable and Reusable (FAIR). The work of the EOSCpilot project to define a core set of metadata properties – the EOSC Dataset Minimum Information or EDMI – that are “sufficient to enable data to be findable by users and suitably ‘aware’ programmatic services” is a good start [3]. The Australian Research Data Commons (ARDC) established in 2018, subsuming the Australian National Data Service (ANDS), also has a similar vision.
My Vision for CODATA
I very much support the three major strategic programs put forward in CODATA’s Strategic Plan 2013 – 2018, namely:
- Data Principles and Practice
- Frontiers of Data Science
- Capacity Building
However, given the promising developments of the last five years it is now time to develop a third strategic plan covering the next five years of the CODATA organization. Development of this new strategic plan must be a major priority for CODATA and it will be important to reach out to all the relevant national and international stakeholder organizations for their input. However, in addition to CODATA’s traditional stakeholders, I would also like to learn from the experience of other major efforts in this space. For example, from the US, this could include input from the NIH’s National Library of Medicine, the DOE’s OSTI organization and the NSF’s DataONE project. From Europe, there will be much activity in creating an implementation of the European Open Science Cloud (EOSC). I would also look for input from other major data science initiatives in Asia and Australia.
In addition to developing detailed plans and deliverables for the three broad CODATA priority areas for the next five years, I would like to give my support to two other areas. During my career in data-intensive science – in the UK with e-Science and in my work with Microsoft Research in the US – I have worked closely with universities and funding agencies in Europe, North and South America, Asia and Australia. I now think it is important to dedicate more attention to Africa where I think CODATA can play a significant role. I am therefore personally very supportive of the existing CODATA initiative to develop an African Open Science Platform and would look for ways to extend this initiative and increase its impact. One way in which to do this is to harness CODATA’s global reach and influence which can successfully bring together countries at many different levels of economic development. The international SKA project will also generate many interesting computing, data science and networking challenges in Africa.
The second focus I would like to develop is related to my present role as leader of the Scientific Machine Learning research group at RAL. There is now much activity world-wide in the application of the latest advances in AI and Machine Learning technologies to scientific data. This is one of the few areas where the academic research community has large and complex data sets that can compete with the ‘Big Data’ available to industry. Extracting new scientific insights from these datasets will require the use of advanced statistical techniques, including Bayesian methods and ‘deep learning’ technologies. In addition, an extensive education program to train researchers in the application of these data analytic technologies will be necessary and can build upon practical experience in applying such methods to ‘Big Scientific Data.’ In this way CODATA can help train a new generation of data analysts who are not only able to generate new insights from scientific data but also to spur innovation with industry and aid economic development.
While at Microsoft Research, I was a founding Board member of the RDA organization. As an RDA Board member, I liaised extensively with both the NSF in the USA, and with the Commission in Europe, and assisted in facilitating the constructive cooperation of RDA with CODATA. I will therefore bring extensive management experience to the leadership of CODATA – from my experience in the university sector as research group leader, department chair and dean of engineering, in UK research funding councils as a program director and chief data scientist, and in industry as manager of a globally distributed outreach team. I am disappointed to see the absence of many European countries from the CODATA membership and, through my experience in European research projects, I would seek to encourage these missing nations to become members of the organization. In addition, in my role at Microsoft Research, I spent considerable time visiting universities and funding agencies in Central and South America, and in Asia. I believe there is considerable potential to interest non-member countries in these regions in the relevance of the data science agenda of CODATA. Finally, although I will certainly bring my vision, enthusiasm and energy to the role of CODATA President, I believe that we must harvest the energy and enthusiasm of the entire CODATA community to take the organization forward to a new level of influence and effectiveness.
My Background
I am standing for election to the CODATA Presidency because I have long been an advocate for Open Access and Open Science. My passion for this topic and for the era of ‘Big Scientific Data’ dates back to the years from 2001 to 2005 when I was director of the UK’s eScience program. With Anne Trefethen, I wrote a paper in 2003 with the title “The Data Deluge: An e-Science Perspective”. This paper was certainly one of the earliest papers to talk about the transformative effects on science of the imminent deluge of scientific data [4]. In 2006, I was invited to give a keynote talk on eScience at the CODATA Conference in Beijing. While a Vice President in Microsoft Research, we celebrated the achievements of my late colleague, the Turing Award winner Jim Gray, by publishing a collection of essays in 2009 that illustrated the emergence of a new ‘Fourth Paradigm’ of Data-Intensive Science [4].
During the eScience program, which received significant funding from both the UK Research Councils and from Jisc, the UK research community explored many issues about the scientific data pipeline that are still important and relevant today. One project, for example, examined the preservation and sharing of scientific workflows. Another project looked in detail at recording the provenance of a dataset. This effort ultimately led in 2013 to the emergence of the W3C ‘PROV’ standard for provenance. Several other eScience projects explored the use of RDF and semantic web technologies such as OWL and SPARQL for enhancing research metadata. Although these technologies have proved popular with several academic research communities, it is probably fair to say that they have not so far been broadly adopted by most research communities nor by the major IT companies. In my role as chair of Jisc’s research committee, I supported the establishment of the Digital Curation Centre (DCC) in Edinburgh in 2004. The DCC was one of the first organizations to propose a set of guidelines for scientific data management plans (DMPs). The Jisc research committee also funded the National Centre for Text Mining (NaCTeM) in Manchester which offers a broad range of text-mining services. In the age of ‘Big Scientific Data’, high-bandwidth, end-to-end networking performance is an increasingly necessary element of a nation’s e-infrastructure. As a result, the Jisc research committee funded Janet, the UK’s NREN, to follow the lead of SURFnet in the Netherlands by introducing optical fibre ‘lambda’ technology. Janet can now provide dedicated ‘lightpath’ support to users requiring long-term, persistent high-volume data transfers between locations. I believe that these e-Science examples still have relevance to CODATA and to the practice of data science today.
Progress towards Open Science, Open Access and ‘Open’ Data
Open science must start with genuine open access to the full text of research papers. Before becoming Director of the UK’s eScience program, I was Head of Department of the Electronics and Computer Science (ECS) Department and then Dean of Engineering at the University of Southampton. Recognizing the crisis that university library budgets were facing in terms of rising journal subscriptions, with the support of Wendy Hall, Stevan Harnad and Les Carr, the ECS Department funded and developed the well-known ePrints repository software and established one of the first ‘Green Open Access’ institutional repositories. In the UK, there is now wide-spread deployment of university research repositories that contain the full text of research papers, albeit with access usually subject to a publisher embargo period of 6 or 12 months.
By contrast, in the US, a historic memo from the White House Office of Science and Technology Policy (OSTP) in 2013 required US funding agencies “to develop a plan to support increased public access to the results of research funded by the Federal Government.” More importantly for CODATA’s agenda, the memo also specified that the ‘results of research’ include not only the scientific research papers but also the accompanying research data. It defined research data as “the digital recorded factual material commonly accepted in the scientific community as necessary to validate research findings including data sets used to support scholarly publications, but does not include laboratory notebooks, preliminary analyses, drafts of scientific papers, plans for future research, peer review reports, communications with colleagues, or physical objects, such as laboratory specimens.”
The OSTP memo has led to all the major US funding agencies developing open science policies and establishing research repositories that contain the full text of research papers linked to the corresponding datasets generated by the researchers that they fund. The two most prominent repository systems are the National Institutes of Health’s PubMed Central with its associated databases, and the Department of Energy’s PAGES system managed by the Office of Scientific and Technical Information (OSTI). In contrast to this US funding agency centred view, UK Research Councils now require all researchers to have a Data Management Plan in their research proposals and look to the universities and specialist subject repositories to be responsible for the outputs of research that they fund. For example, one Council, the Engineering and Physical Sciences Research Council, now requires that “Research organizations will ensure that EPSRC-funded research data is securely preserved for a minimum of 10 years from the date that any researcher ‘privileged access’ period expires”.
The developments described above have taken place over the last five years and constitute significant progress toward open science. I am therefore optimistic that CODATA, together with WDS and RDA, and supported by national and international research funding agencies, can continue to make major strides towards changing the culture of researchers about their research data. My optimism is further fuelled by the steady increase in research registrations for ORCID IDs and DOIs for datasets and software by university researchers.
Two very recent developments are also exciting. The first is the announcement of Science Europe’s ‘cOAlition’ for open access. Eleven European research funding agencies have agreed to focus their open science efforts on the very ambitious ‘Plan S’ – which aims at ‘Making Open Access a Reality by 2020’ [5]. The second notable development is Google’s introduction of a new Dataset Search service which has the potential to become a significant aid to data discoverability. The service makes use of the industry supported ‘schema.org’ initiative which aims to add some semantic information to the metadata describing the dataset.
“Schema.org is a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet, on web pages, in email messages, and beyond. Schema.org vocabulary can be used with many different encodings, including RDFa, Microdata and JSON-LD. These vocabularies cover entities, relationships between entities and actions, and can easily be extended through a well-documented extension model” [7].
The recent work by the ELIXIR collaboration on the Bioschemas extension to schema.org is intended to improve data interoperability in life sciences research. Bioschemas is a collection of specifications that provide guidelines to facilitate a more consistent adoption of schema.org markup within the life sciences [8]. Such initiatives and are important indicators of the direction of open science. I therefore believe that a pragmatic approach to machine actionable metadata that is based on schema.org and subject-specific extensions represents a practical way forward for the majority of scientific research communities.
Tony Hey
Rutherford Appleton Laboratory
Science and Technology Facilities Council
Harwell Campus
Didcot, OX11 0QX, UK
References
[1] CODATA Mission statement, http://www.codata.org/about-codata/our-mission
[2] “The Fourth Paradigm: Data-Intensive Scientific Discovery”, edited by Tony Hey, Stewart Tansley and Kristin Tolle, published by Microsoft Research, 2009, ISBN: 978-0-9825442-0-4
[3] EOSCpilot, D6.3: 1st Report on Data Interoperability: Findability and Interoperability, https://eoscpilot.eu/sites/default/files/eoscpilot-d6.3.pdf
[4] Tony Hey and Anne Trefethen. “The Data Deluge: An e-Science Perspective”, Chapter in “Grid Computing – Making the Global Infrastructure a Reality”, edited by F Berman, G C Fox and A J G Hey, Wiley, pp.809-824 (2003)
[5] Plan-S, https://www.scienceeurope.org/wp-content/uploads/2018/09/cOAlitionS_Press_Release.pdf
[6] Google Dataset Search, https://ai.googleblog.com/2018/09/building-google-dataset-search-and.html
[7] Schema.org, https://schema.org/
[8] Bioschemas, http://bioschemas.org/
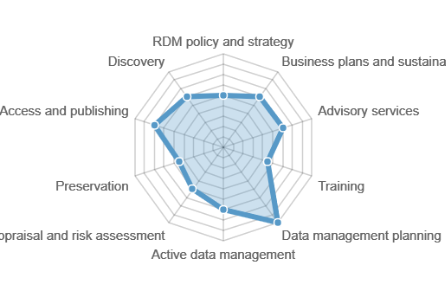 Institutions now have a new means at their disposal to aid them in assessing their research data management initiatives, the Evaluating RDM Tool.
Institutions now have a new means at their disposal to aid them in assessing their research data management initiatives, the Evaluating RDM Tool.



 Data visualization uses uncomplicated language to simplify things into concepts that can be easily grasped in graphical format enabling easy understanding. It also can provide insight and ability to understand cross-cutting complex issues and identify patterns to inform formation of successful decision making in terms of strategies and solutions. Prior to the use of the current formal written language, pictures (a form of visualization) were the key medium for sharing history, plans and ideas. Recognising the immense importance of data visualization, CODATA Kenya and the ICT centre of Open Data (iCEOD) under the leadership of its Director Prof. Muliaro Wafula in Jomo Kenyatta University of Agriculture and Technology, who is also the Chair of CODATA Kenya and an elected member of the CODATA International Executive Committee, organised the first Data, Information and Scientific Visualization Symposium in Afriuca that was held from 20-21 August 2018 in Nairobi, Kenya.
Data visualization uses uncomplicated language to simplify things into concepts that can be easily grasped in graphical format enabling easy understanding. It also can provide insight and ability to understand cross-cutting complex issues and identify patterns to inform formation of successful decision making in terms of strategies and solutions. Prior to the use of the current formal written language, pictures (a form of visualization) were the key medium for sharing history, plans and ideas. Recognising the immense importance of data visualization, CODATA Kenya and the ICT centre of Open Data (iCEOD) under the leadership of its Director Prof. Muliaro Wafula in Jomo Kenyatta University of Agriculture and Technology, who is also the Chair of CODATA Kenya and an elected member of the CODATA International Executive Committee, organised the first Data, Information and Scientific Visualization Symposium in Afriuca that was held from 20-21 August 2018 in Nairobi, Kenya.


 Prof. Xiaoru Yuan, from the Peking University in China gave a keynote speech titled ‘Data visualization for Everyone’ which demonstrated how visualization is in the middle of technology and humans. He referred to data visualization conferences held in Kyoto, Beijing and now Nairobi to emphasize how visualization is happening globally. Data visualization is relevant to researchers example in dissemination of scientific work and is also relevant to citizens in traffic jam management, discussion maps, and flood mapping. The presentation noted the existence of data visualization for non-programmers.
Prof. Xiaoru Yuan, from the Peking University in China gave a keynote speech titled ‘Data visualization for Everyone’ which demonstrated how visualization is in the middle of technology and humans. He referred to data visualization conferences held in Kyoto, Beijing and now Nairobi to emphasize how visualization is happening globally. Data visualization is relevant to researchers example in dissemination of scientific work and is also relevant to citizens in traffic jam management, discussion maps, and flood mapping. The presentation noted the existence of data visualization for non-programmers.


 This is the fourteen in the series of short statements from candidates in the forthcoming CODATA Elections at the General Assembly to be held on 9-10 November in Gaborone, Botswana, following
This is the fourteen in the series of short statements from candidates in the forthcoming CODATA Elections at the General Assembly to be held on 9-10 November in Gaborone, Botswana, following 