|
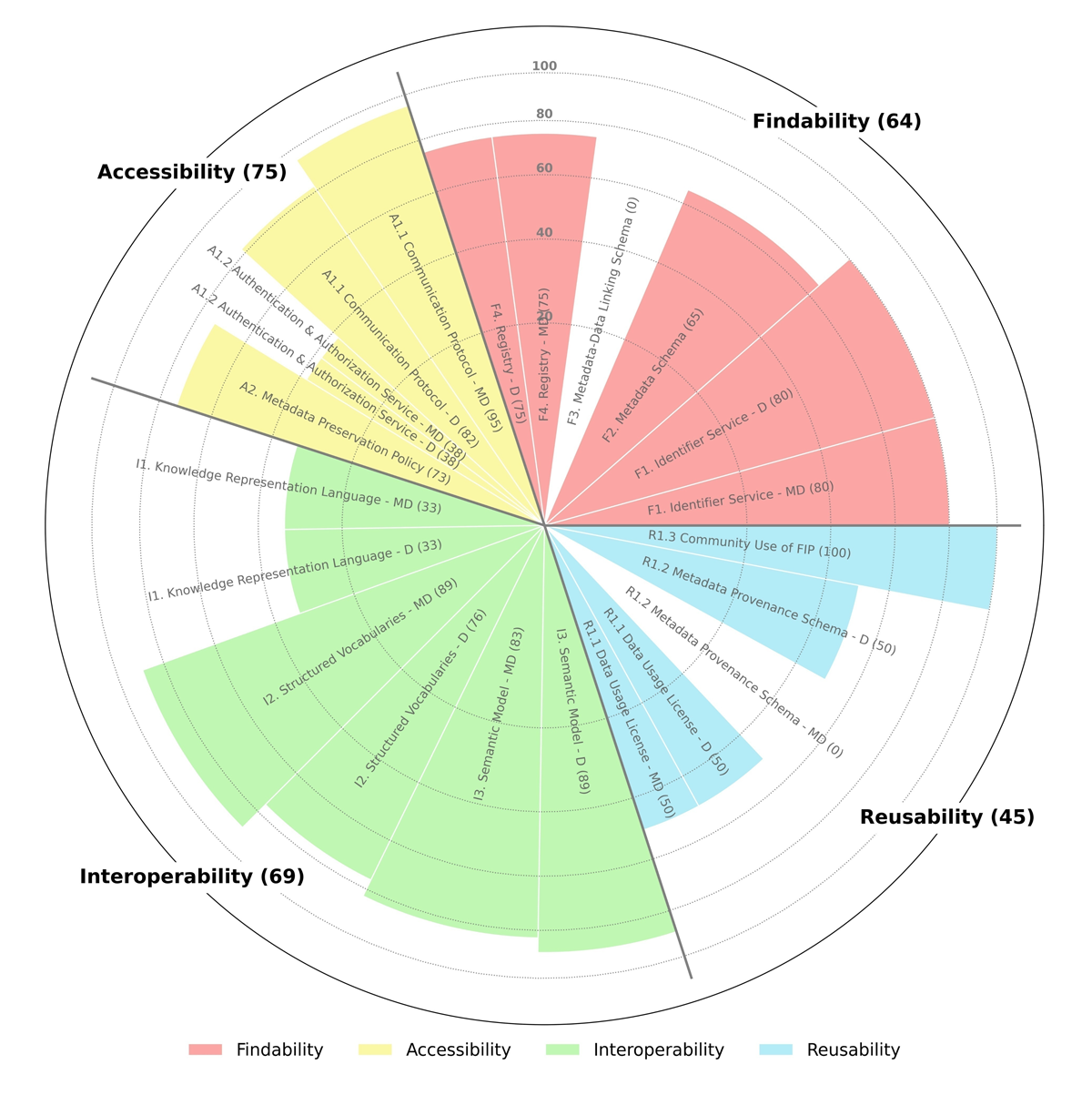
 Title: FIP Check: A Rubric-Based Tool for Assessing FAIR Implementation Profiles and Enabling Resources Title: FIP Check: A Rubric-Based Tool for Assessing FAIR Implementation Profiles and Enabling Resources
Author: Sungha Kang, John Graybeal, Barbara Magagna, Erik Schultes, Nancy Hoebelheinrich, Chris Erdmann, Ismael Kherroubi Garcia, Julianne Christopher, Christine R. Kirkpatrick
URL: http://doi.org/10.5334/dsj-2026-008 |
|
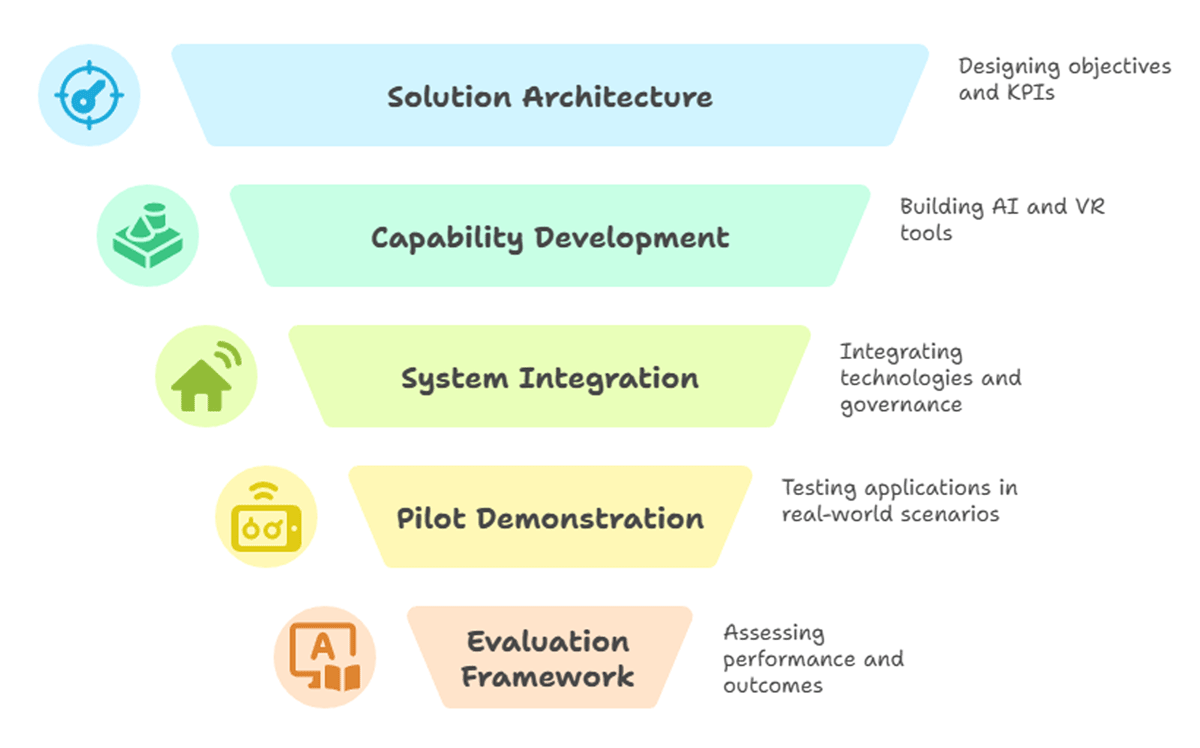
 Title: Development of Technology Convergence Assessment Framework for Poly crisis Title: Development of Technology Convergence Assessment Framework for Poly crisis
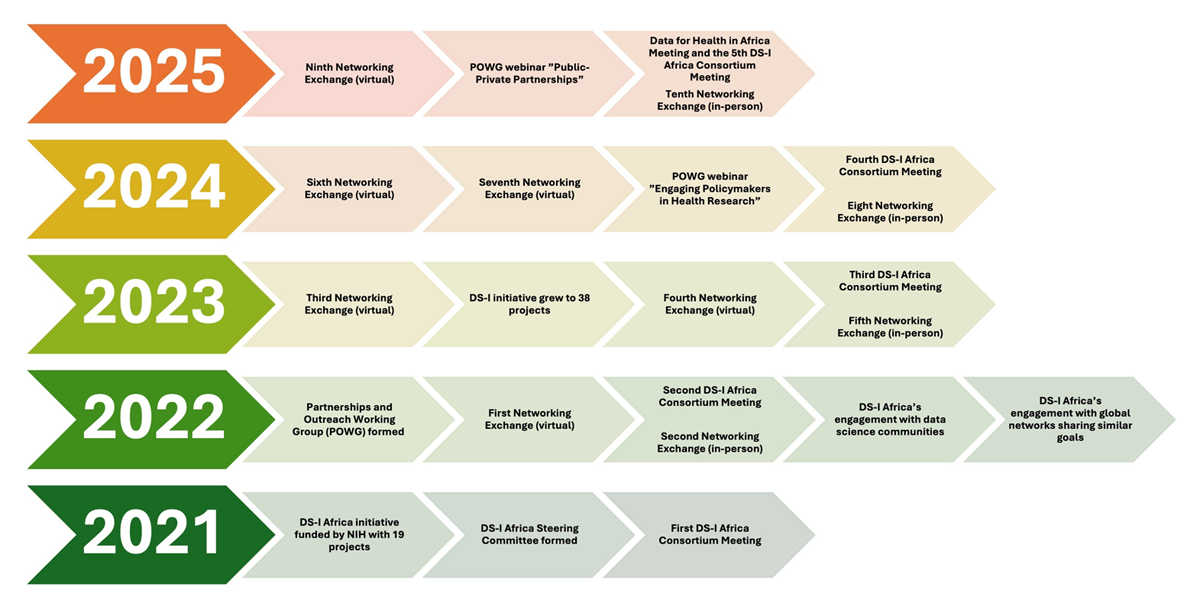
Author: Rania Elsayed Ibrahim, Tshiamo Motshegwa, Abdelaziz Elfadaly, Alaa A. Elbiomy, Mai Ramadan Ibraheem
URL: http://doi.org/10.5334/dsj-2026-007 |
|
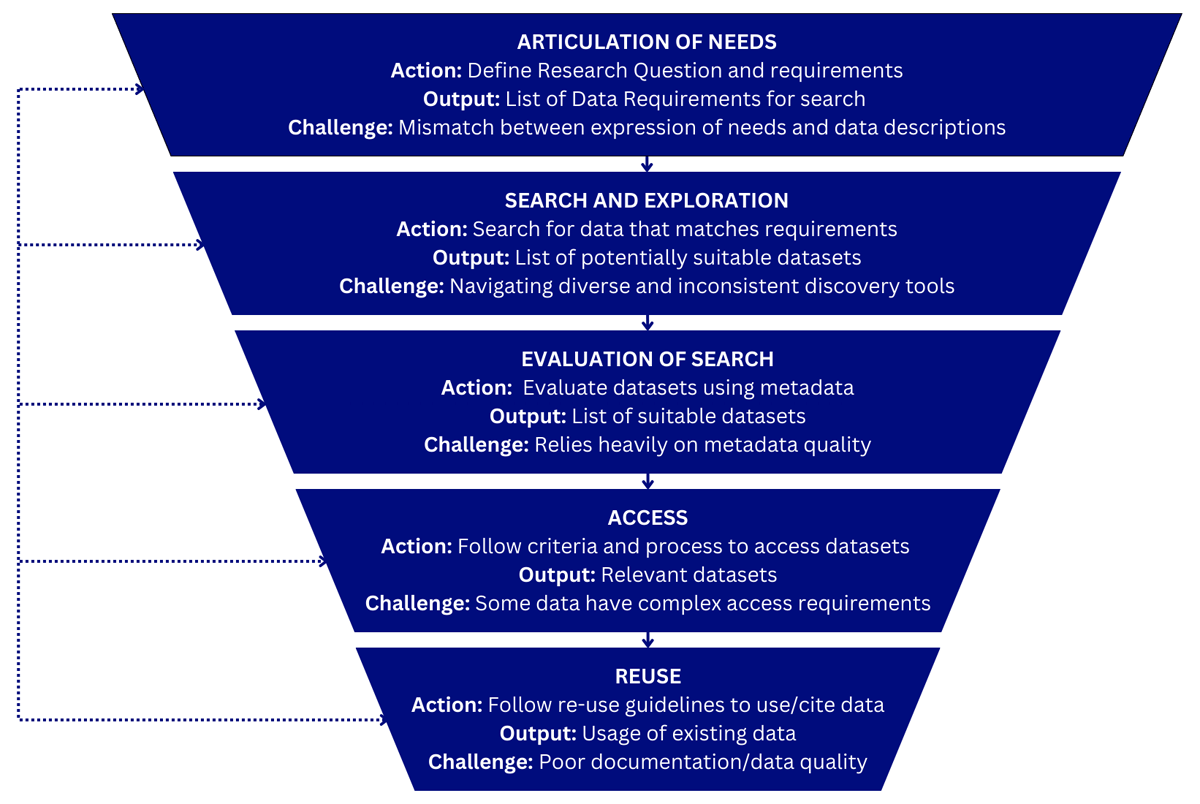
 Title: Bridging the Data Discovery Gap: User-Centric Recommendations for Research Data Repositories Title: Bridging the Data Discovery Gap: User-Centric Recommendations for Research Data Repositories
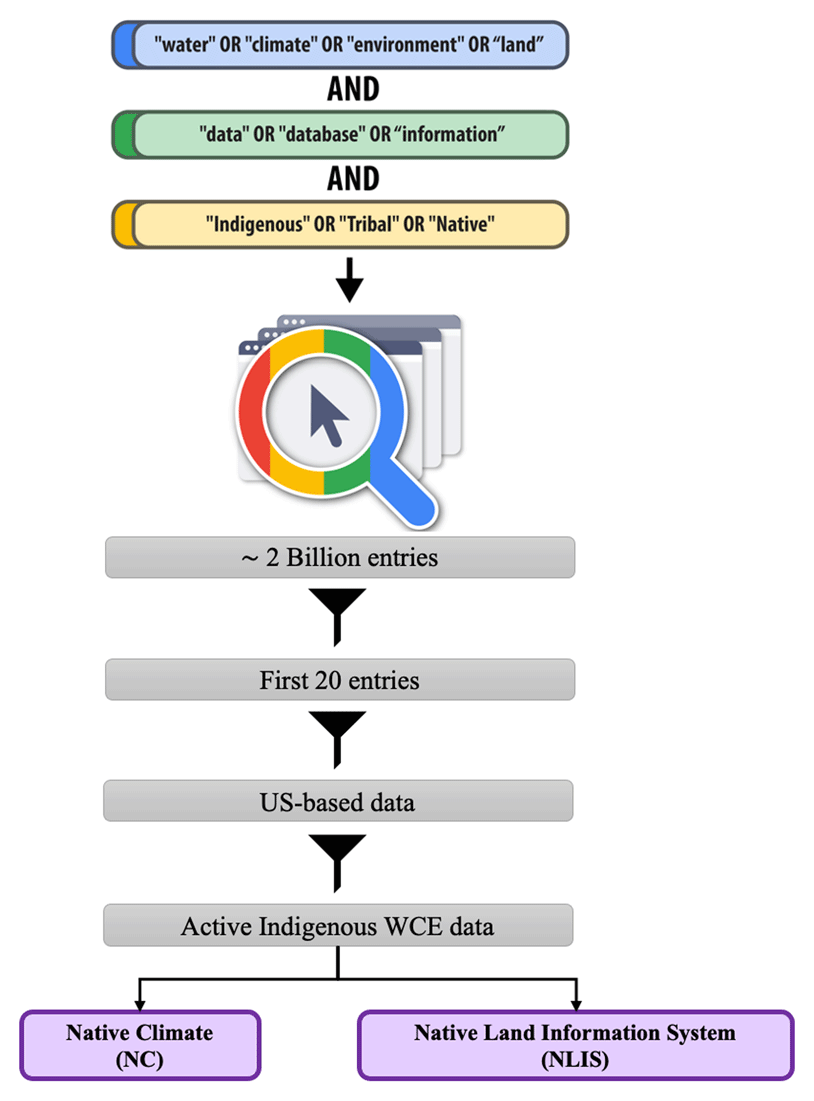
Author: Mingfang Wu, Felicitas Löffler, Brigitte Mathiak, Fotis Psomopoulos, Uwe Schindler, Amir Aryani, Jordi Bodera Sempere, Antica Culina, Andreas Czerniak, Chris Erdmann, Kathleen Gregory, Nick Juty, Allyson Lister, Ying-Hsang Liu, Samantha Pearman-Kanza
URL: http://doi.org/10.5334/dsj-2026-006 |
|
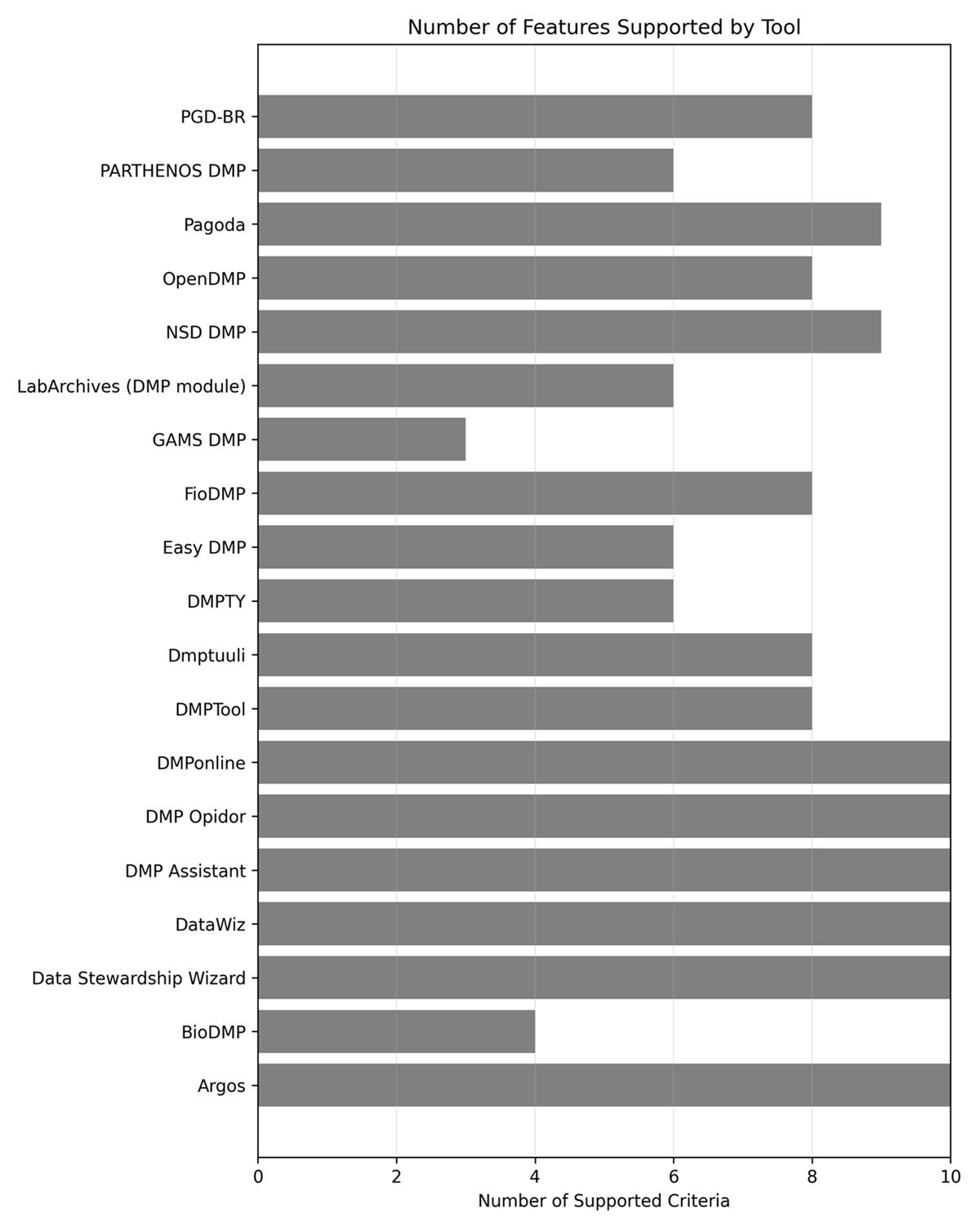
 Title: Essential Aspects of Tools for Developing Scientific Data Management Plans Title: Essential Aspects of Tools for Developing Scientific Data Management Plans
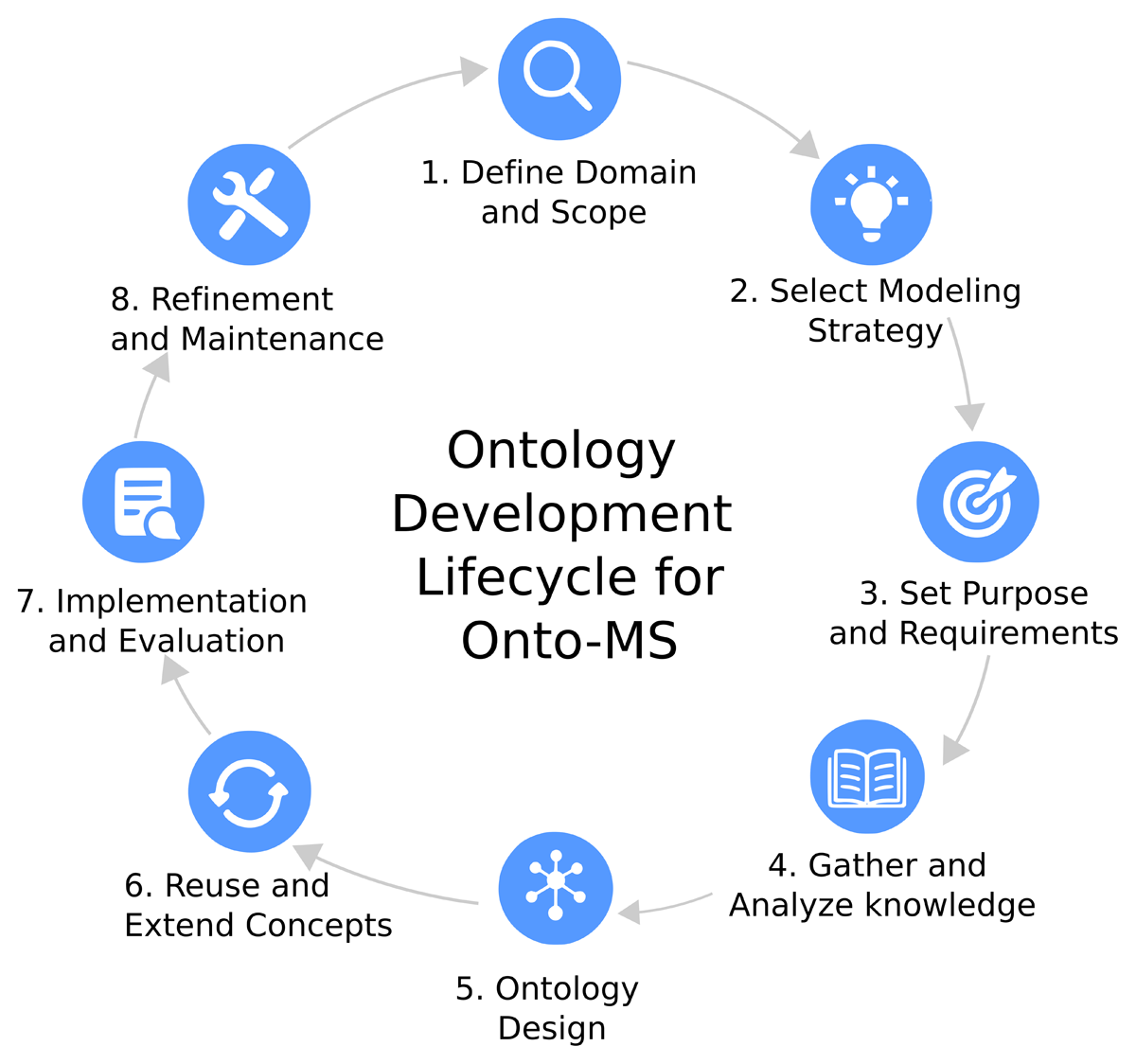
Author: Fabiano Couto Corrêa Silva, Sandra de Albuquerque Siebra, Laura Vilela Rodrigues Rezende, Alexandre Faria de Oliveira, Denise Oliveira de Araújo
URL: http://doi.org/10.5334/dsj-2026-005 |
|
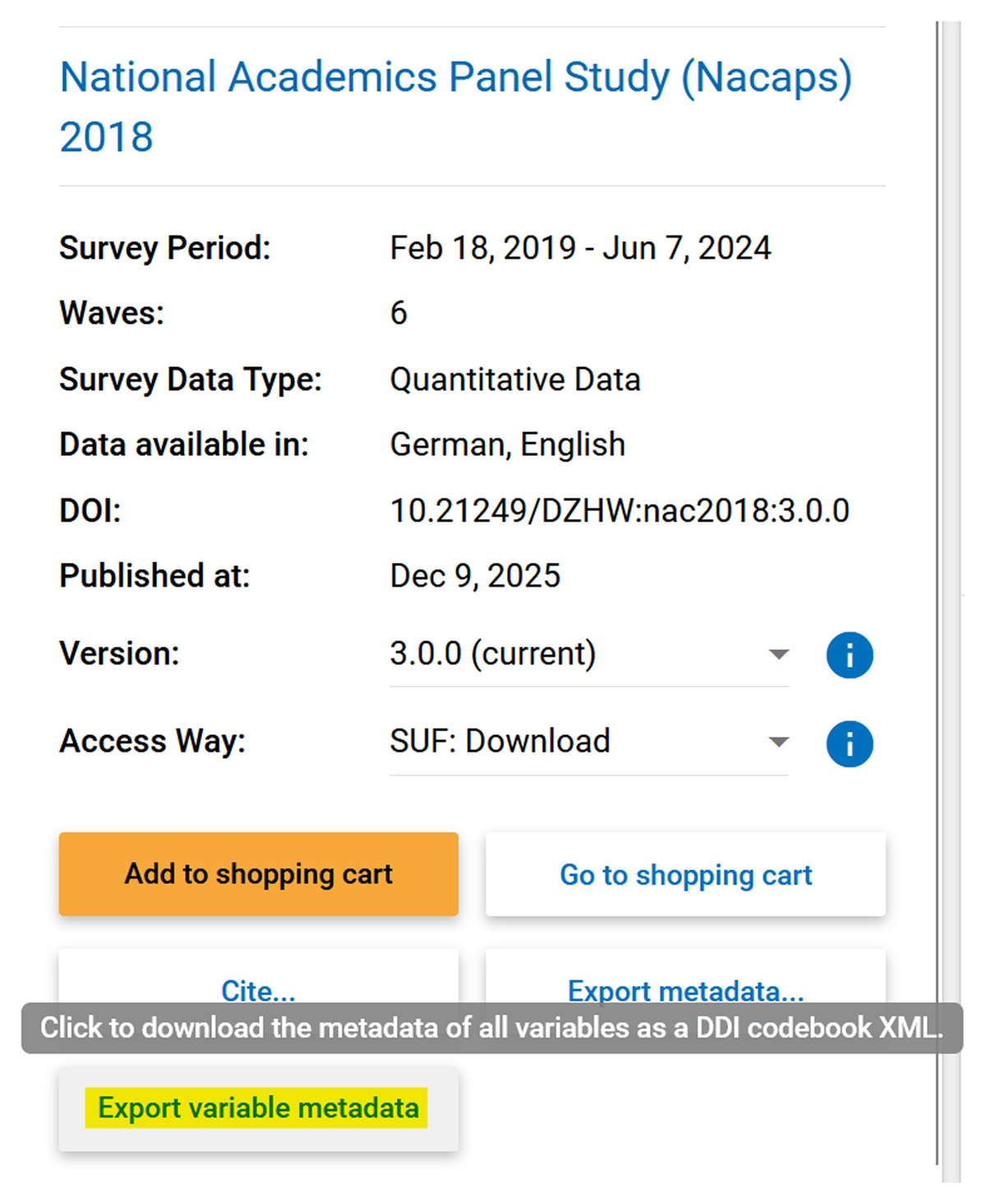
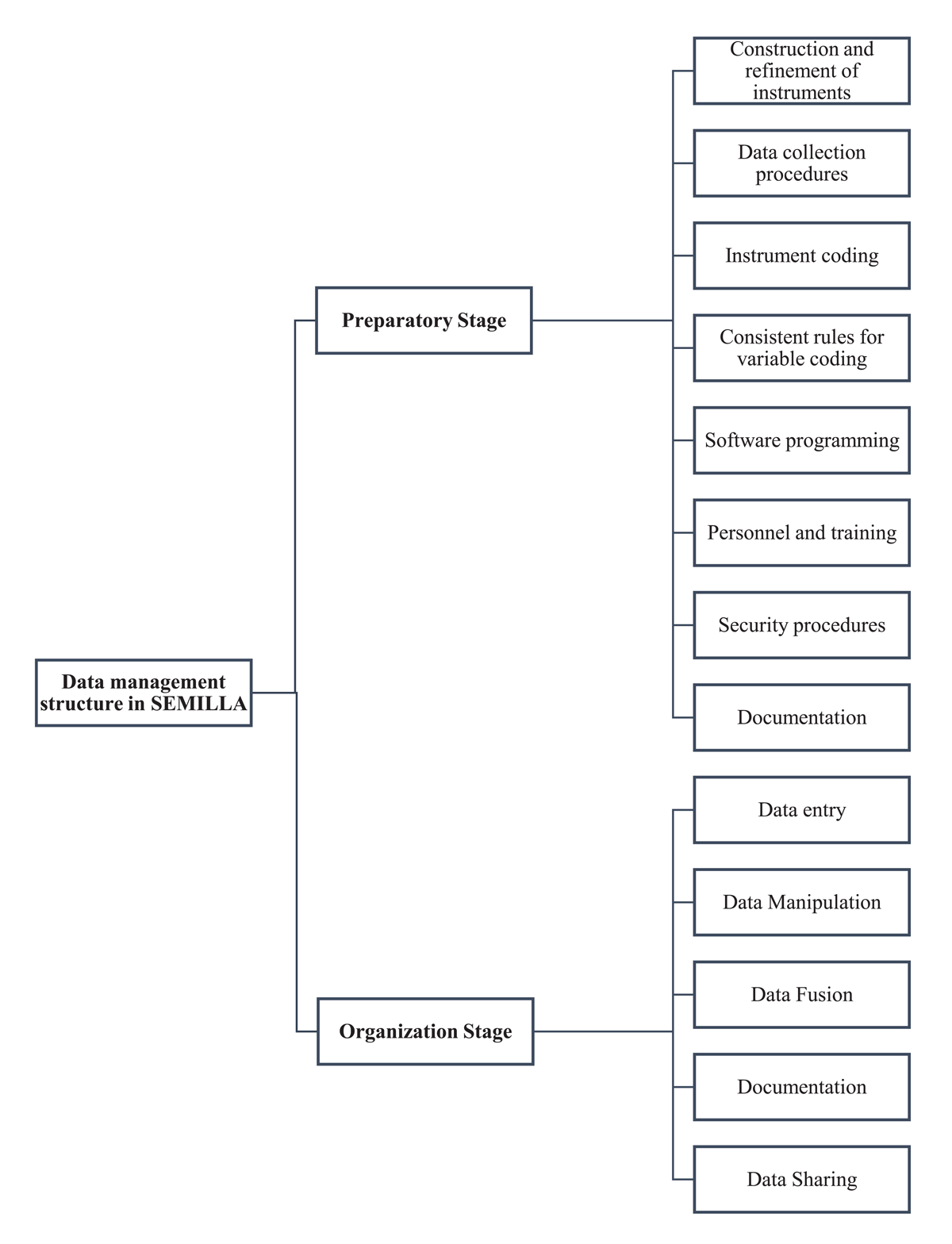
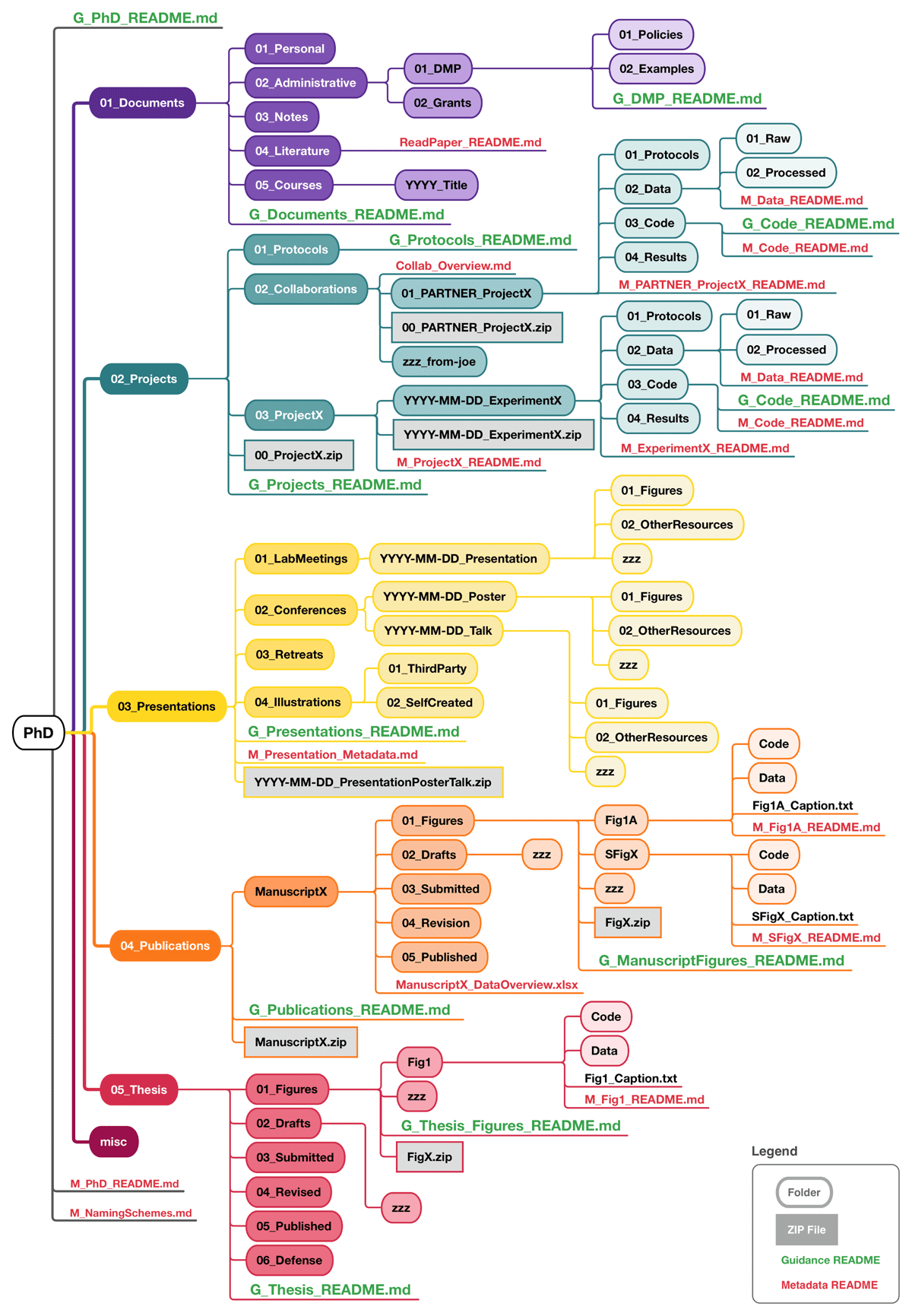
 Title: Data Management in a Community-Based Birth Cohort: What the SEMILLA Study Teaches Us Title: Data Management in a Community-Based Birth Cohort: What the SEMILLA Study Teaches Us
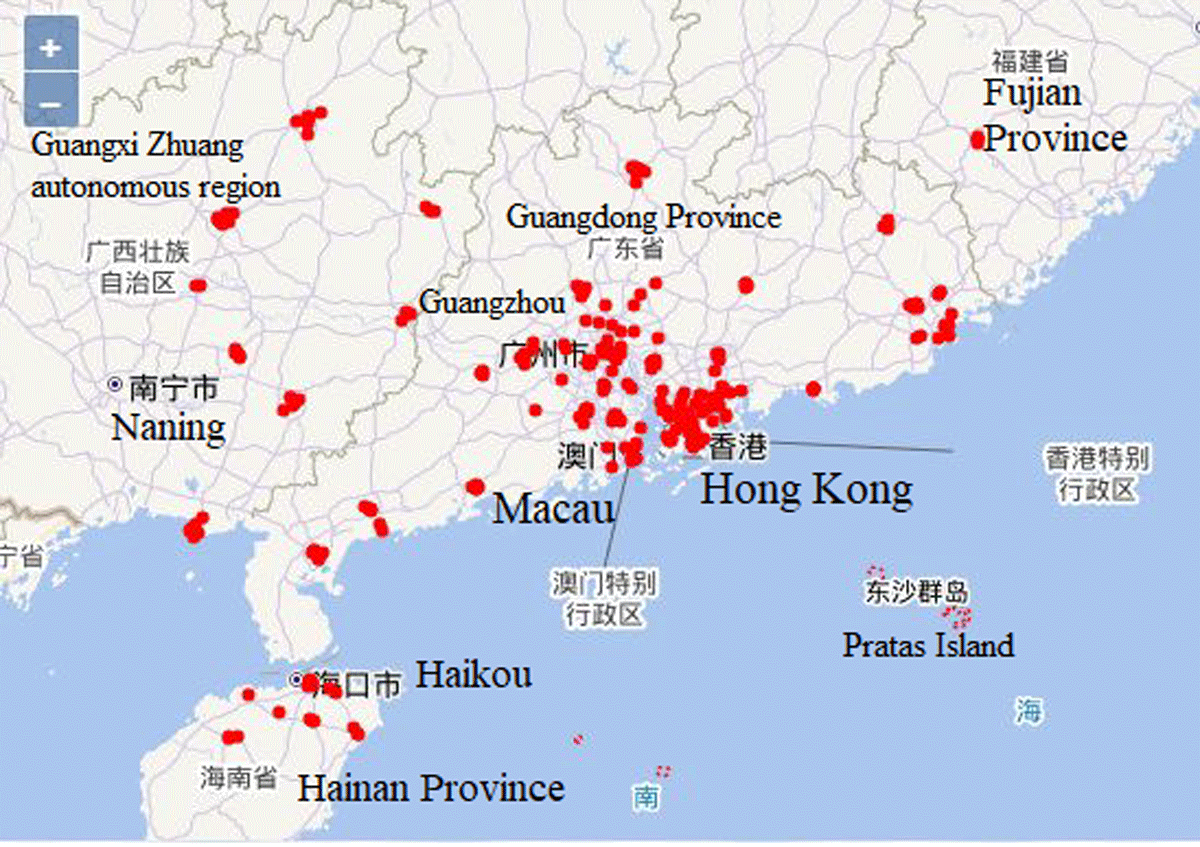
Author: Nataly Cadena, Fadya Orozco, Stephanie Montenegro, Fabián Muñoz, Alexis J. Handal
URL: http://doi.org/10.5334/dsj-2026-004 |
|
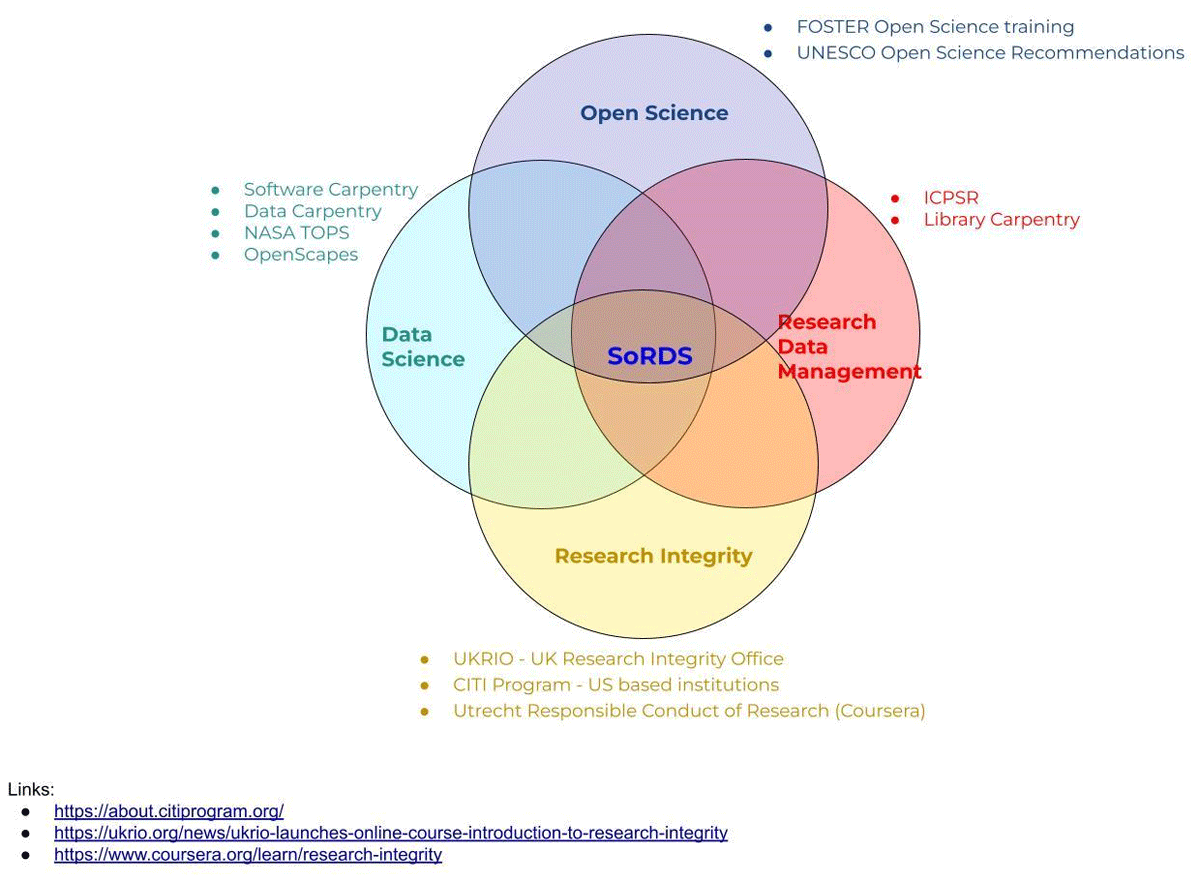
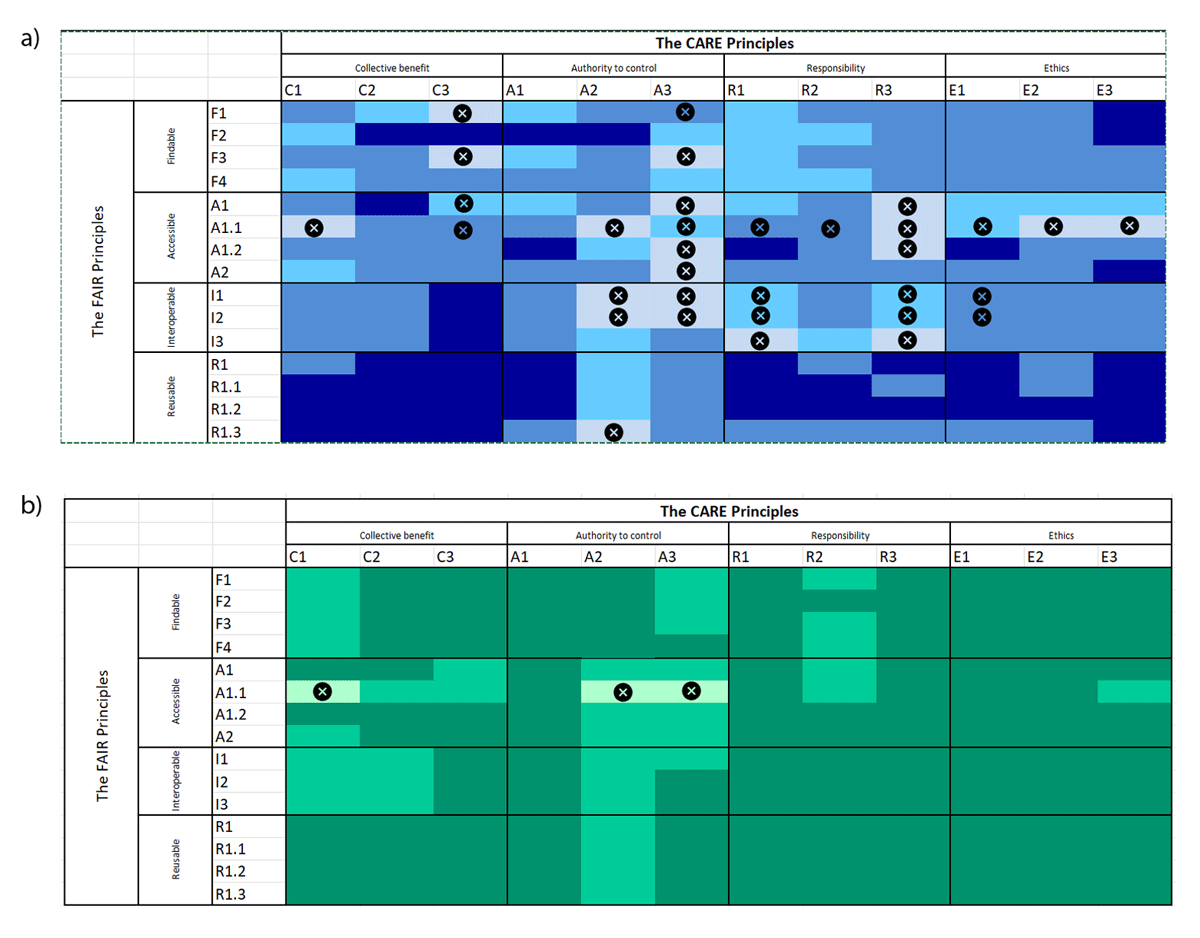
 Title: Implementing the FAIR and CARE Principles Simultaneously: Emerging Insights from IPBES Title: Implementing the FAIR and CARE Principles Simultaneously: Emerging Insights from IPBES
Author: Renske M. Gudde, Rainer M. Krug, Yanina V. Sica, Howard P. Nelson, Félicie Françoise, Manuela Gómez-Suárez, Aidin Niamir
URL: http://doi.org/10.5334/dsj-2026-003 |

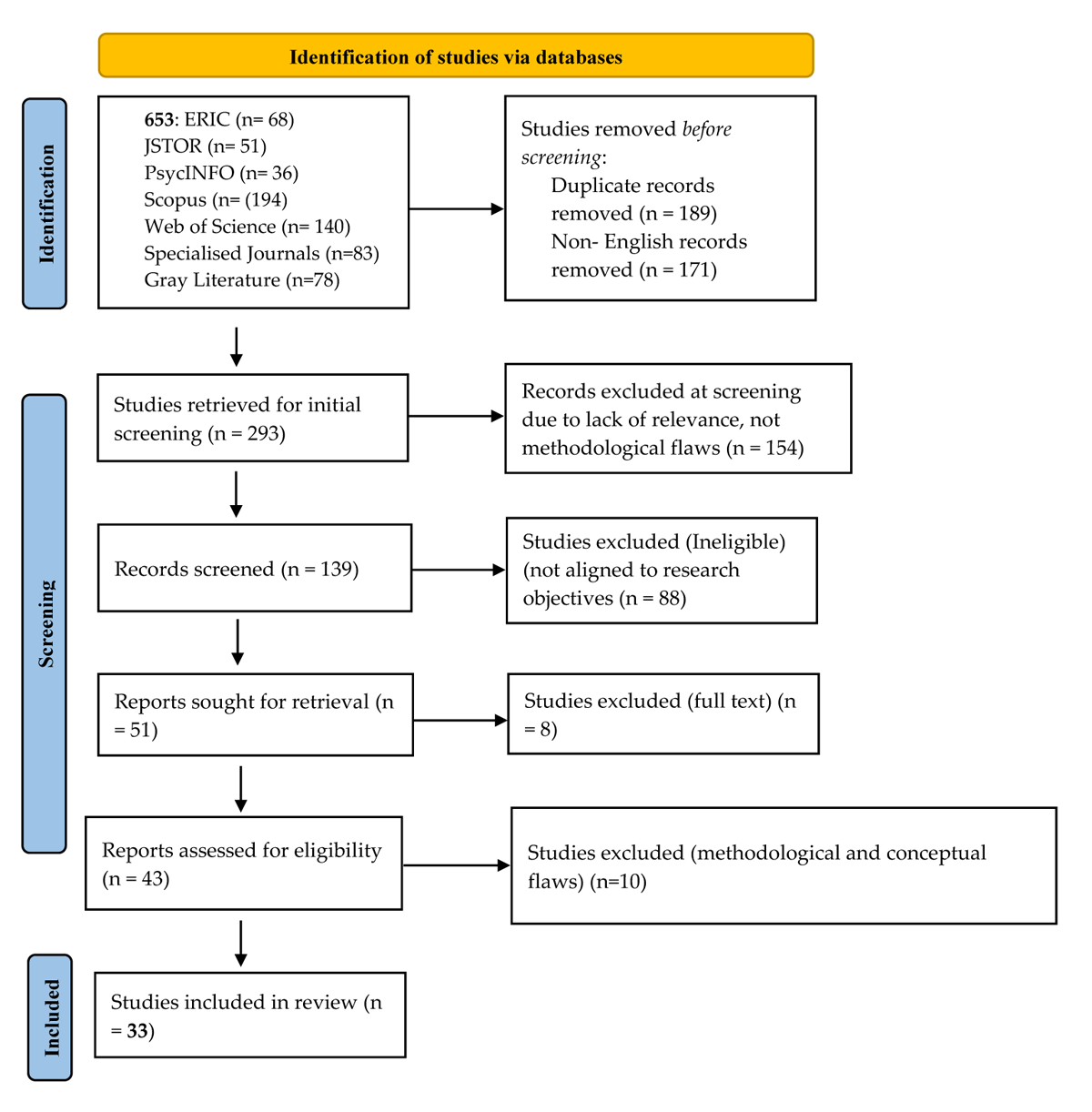 Title: Universal Mandates vs. Contextual Realities: A Scoping Review of Ethical Tensions and Power Asymmetries in Global Open Science
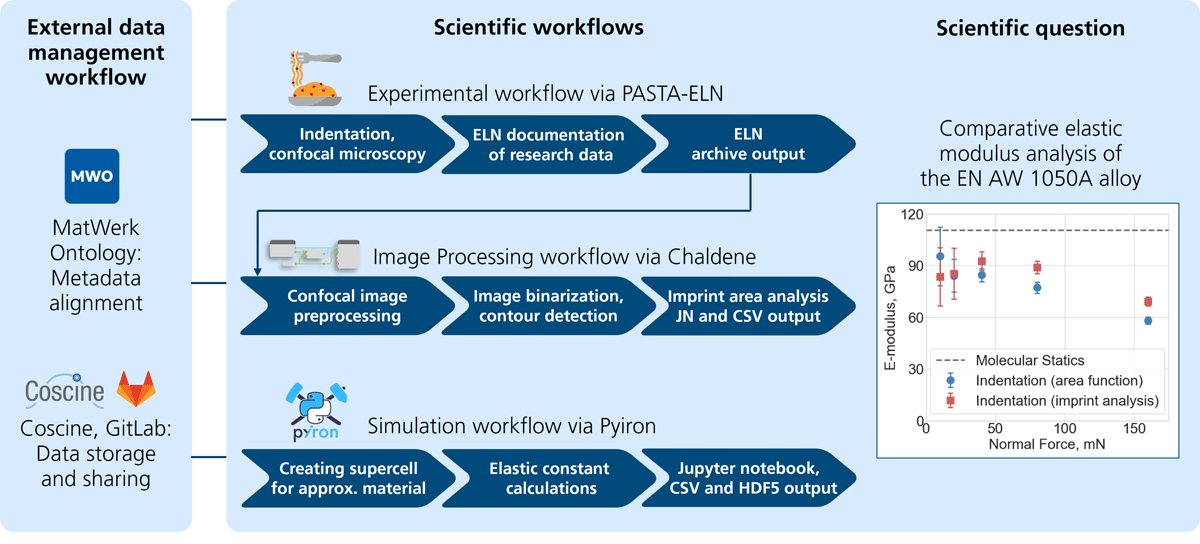
Title: Universal Mandates vs. Contextual Realities: A Scoping Review of Ethical Tensions and Power Asymmetries in Global Open Science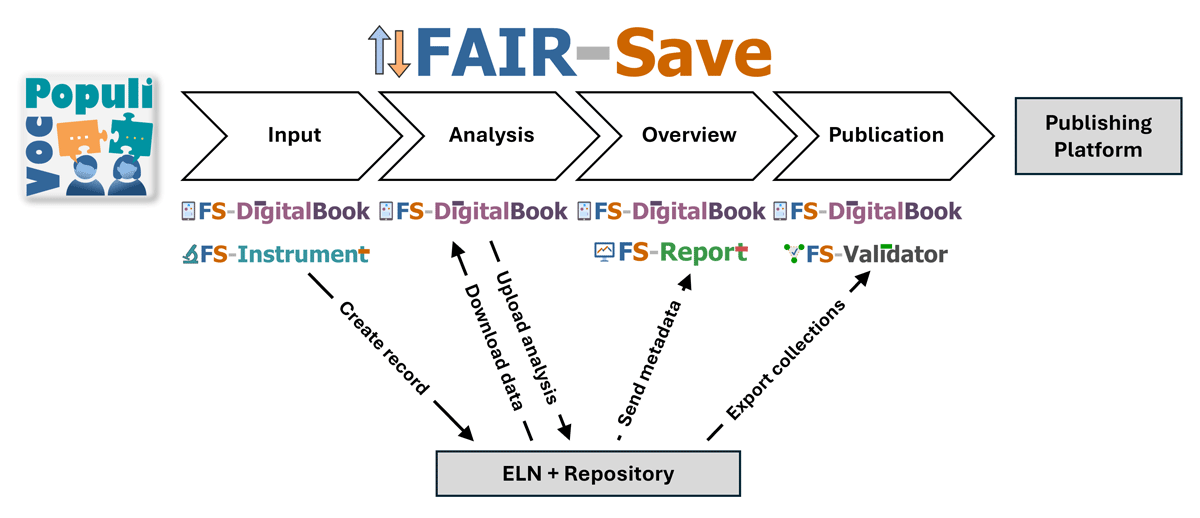 Title: FAIR Data in Action: The User-Centric Software Suite FAIRSave for Fully Digital, Data-Driven Studies in Materials Science
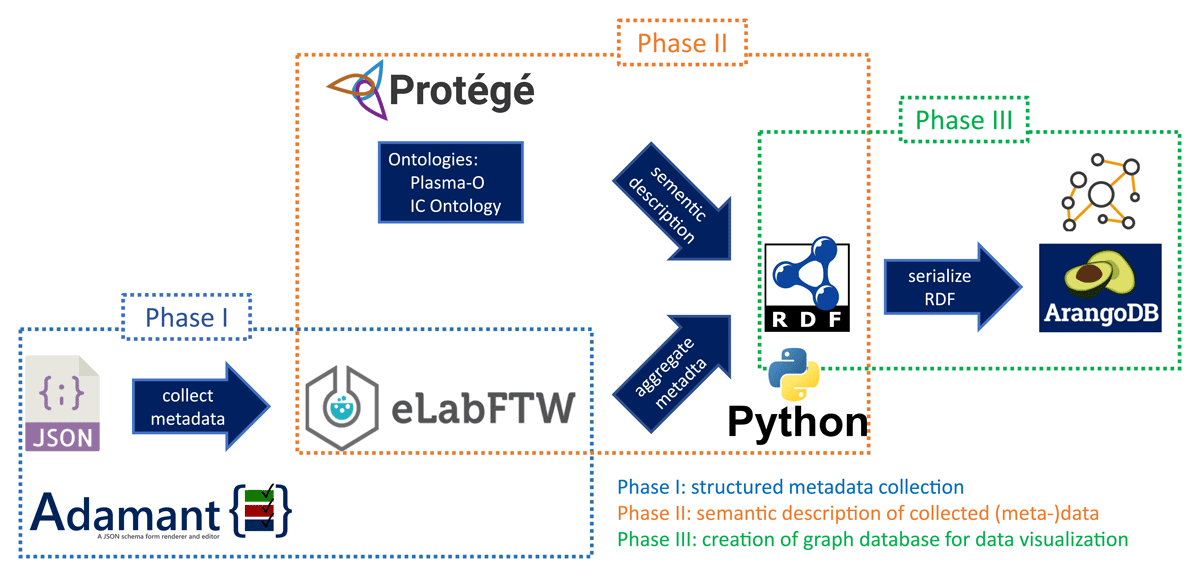
Title: FAIR Data in Action: The User-Centric Software Suite FAIRSave for Fully Digital, Data-Driven Studies in Materials Science