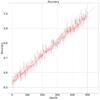
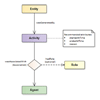
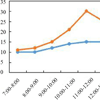
Title: Dataset after Seven Years Simulating Hybrid Energy Systems with Homer Legacy Author: Alexandre Beluco, Frederico A. During F°, Lúcia M. R. Silva, Jones S. Silva, Lúis E. Teixeira, Gabriel Vasco, Fausto A. Canales, Elton G. Rossini, José de Souza, Giuliano C. Daronco, Alfonso Risso URL: http://doi.org/10.5334/dsj-2020-014 |
|
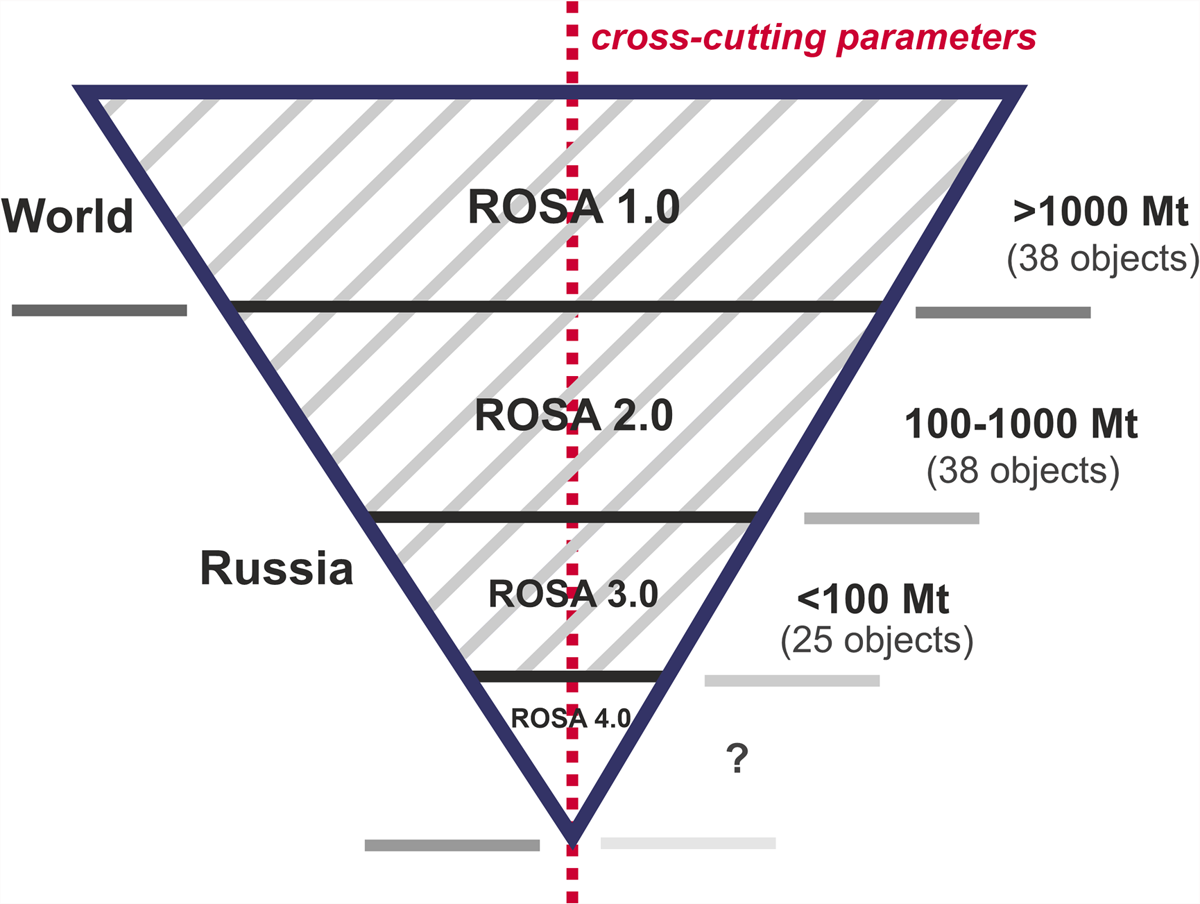 Title: GIS Project ROSA: FAIR Principles in the Petroleum Industry Author: Anastasia Odintsova , Alena Rybkina, Julia Nikolova, Anna Korolkova URL: http://doi.org/10.5334/dsj-2020-013 |
|
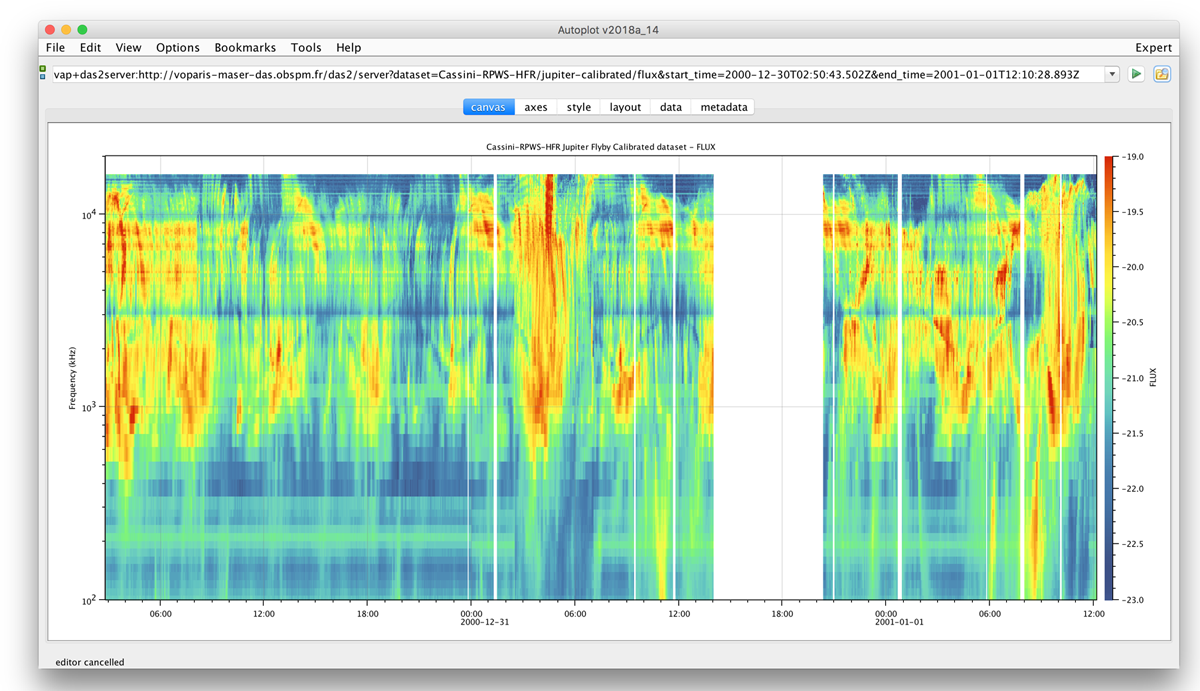 Title: MASER: A Science Ready Toolbox for Low Frequency Radio Astronomy Title: MASER: A Science Ready Toolbox for Low Frequency Radio AstronomyAuthor: Baptiste Cecconi, Alan Loh, Pierre Le Sidaner, Renaud Savalle, Xavier Bonnin, Quynh Nhu Nguyen, Sonny Lion, Albert Shih, Stéphane Aicardi, Philippe Zarka, Corentin Louis, Andrée Coffre, Laurent Lamy, Laurent Denis, Jean-Mathias Grießmeier, Jeremy Faden, Chris Piker, Nicolas André, Vincent Génot, Stéphane Erard, Joseph N. Mafi, Todd A. King, Jim Sky, Markus Demleitner URL: http://doi.org/10.5334/dsj-2020-012 |
|
 Title: Experimental Data of Muon Hodoscope URAGAN for Investigations of Geoffective Processes in the Heliosphere Author: Anna Kovylyaeva , Ivan Astapov, Anna Dmitrieva, Vladimir Borog, Natalia Osetrova, Igor Yashin URL: http://doi.org/10.5334/dsj-2020-011 |
|
 Title: Risk Assessment for Scientific Data Author: Matthew S. Mayernik , Kelsey Breseman, Robert R. Downs, Ruth Duerr, Alexis Garretson, Chung-Yi (Sophie) Hou, Environmental Data Governance Initiative (EDGI) and Earth Science Information Partners (ESIP) Data Stewardship Committee URL: http://doi.org/10.5334/dsj-2020-010 |
|
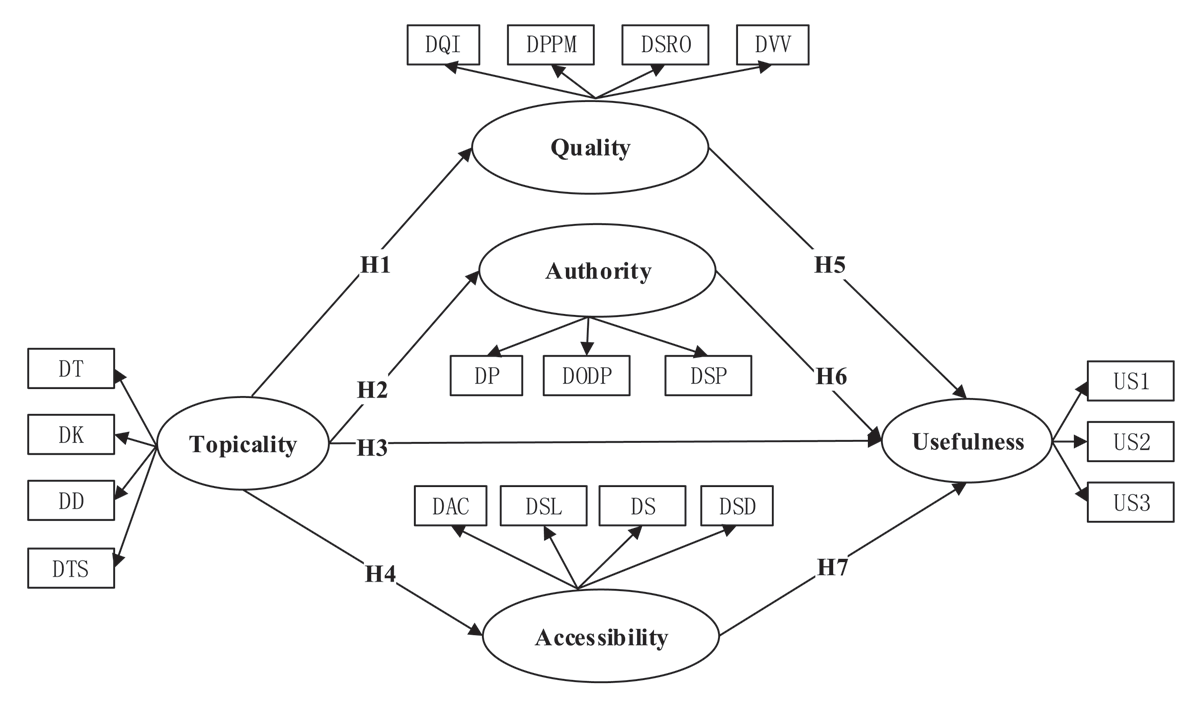 Title: How Do People Make Relevance Judgment of Scientific Data? Author: Jianping Liu , Jian Wang, Guomin Zhou, Mo Wang, Lei Shi URL: http://doi.org/10.5334/dsj-2020-009 |
|
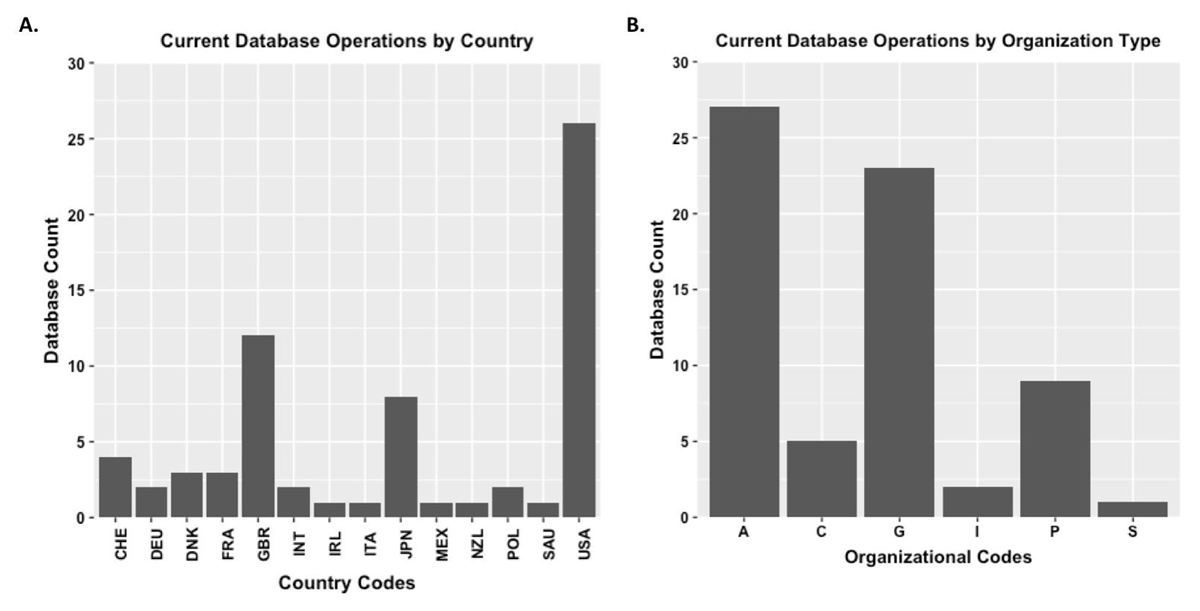 Title: Who Bears the Burden of Long-Lived Molecular Biology Databases? Author: Heidi J. Imker URL: http://doi.org/10.5334/dsj-2020-008 |