The 15th International Conference on Open Repositories, OR2020, will be held in Stellenbosch, South Africa, from 1-4 June 2020. The organisers are pleased to invite you to contribute to the program. This year’s conference theme is:
Open for all
In today’s world, access to knowledge by all is viewed by some as a fundamental freedom and human right. In our societies, open knowledge for all can enable sustainable development and growth on many levels. How well do repositories support knowledge in the service of society? How well do they enable local knowledge sharing and support not only academic use, but also use in education and practice?
Invitation to participate
OR2020 will provide an opportunity to explore and reflect on the ways repositories enable openness for all. We hope that this discussion will give the participants new insights and inspiration, which will help them to play a key role in developing, supporting and sharing an open agenda and open tools for research and scholarship.
We particularly welcome proposals on the overall “Open for All” theme, but also on other administrative, organisational or practical topics related to digital repositories. We are particularly interested in the following sub-themes:
1. Equity and democratization of knowledge
- Accessibility of repositories and their content
- Equity and democratization of knowledge
- Inclusion of marginalized and underrepresented voices
- Local knowledge sharing
- Moving beyond traditional academic content and services, supporting educators and practitioners
- Supporting knowledge in the service of society, encouraging non-academic use
- Enabling access to governmental publications/data
- Addressing language barriers
2. Beyond the repository
- Integration with other open knowledge resources (e.g. Wikimedia and Wikidata)
- Next Generation Repositories, Pubfair
- Convergence and integration with other types of systems (e.g. current research information systems, digital asset management systems, publishing platforms, ORCID)
- Interoperability vs integration
- New models for scholarly sharing
- Data mining, artificial intelligence and machine learning
3. Open and sustainable
- Local systems vs repository as a service
- Securing long-term funding for open infrastructures
- Open business models and governance for open infrastructures
- Sustaining community-based infrastructure
4. Policies, licensing and copyright laws
- Impact of GDPR (General Data Protection Regulation), POPIA (Protection of Personal Information Act) and copyright laws
- Publisher policies, embargoes and rights retention
- Licenses and re-use of content
- Compliance and impact of funder policies (e.g. Plan S) on repositories
5. Discovery, use and impact
- Data/metadata visualization
- Open access discovery, research data discovery
- Tools for researchers and practitioners, interfaces for machines
- Measuring impact particularly outside of the academic context.
- Supporting use by practitioners.
6. Supporting open scholarship and cultural heritage
- Providing access to different types of materials (e.g. research data, scholarly articles, pre prints and overlay journals, open access monographs, theses and dissertations, educational resources, archival and cultural heritage materials, audiovisual materials, software, interactive publications and emerging formats)
- Repositories as digital humanities and open science platforms
- Inclusion of marginalized and underrepresented voices
Submission Process
The Program Committee has provided templates to use for submissions (see below for links). Please use the submission template, and then submit through ConfTool (link coming soon) where you will be asked to provide additional information (such as primary contact and the conference subtheme your submission best fits).
Accepted proposals in all categories will be made available through the conference’s website. Later, the presentations and associated materials will be made available in an open repository; you will be contacted to upload your set of slides or poster. Some conference sessions will be live streamed or recorded, then made publicly available.
After the completion of the conference, we will solicit full papers from a selection of presentation in order to be published in the OR2020 proceedings (open access, no article processing charge) in cooperation with a scholarly publisher. If you are proposing a presentation or panel, you may want to consider whether it could be turned into a full paper.
Submission Categories
Presentations
Presentations make up the bulk of the Open Repositories conference. Presentations are substantive discussions of a relevant topic; successful submissions in past years have typically described work relevant to a wide audience. These typically are placed in a 30 minute time slot (generally alongside two other presentations for a total of 90 minutes). We strongly encourage presentations that can be delivered in 20-25 minutes in order to leave time for questions and discussion.
Presentation proposals should be 2-3 pages.
Panels
Panels are made up of two or more panelists presenting on work or issues where multiple perspectives and experiences are useful or necessary. Successful submissions in past years have typically described work relevant to a wide audience and applicable beyond a single software system. All panels are expected to include diversity in viewpoints, personal background, and gender of the panelists. Panels can be 60 or 90 minutes long. If 60 minutes, the panel may be combined in a session with a presentation.
Panel proposals should be 2-3 pages.
24×7 Presentations
24×7 presentations are 7 minute presentations comprising no more than 24 slides. Successful 24×7 presentations are fast paced and have a clear focus on one idea. 24×7 presentations about failures and lessons learnt are highly encouraged.
Presentations will be grouped into blocks based on conference themes, with each block followed by a moderated question and answer session involving the audience and all block presenters.
Proposals for 24×7 presentations should be one page.
Posters
OR2020 will feature physical posters only. Posters should showcase current or ongoing work that is not yet ready for a full 30 minute presentation. Instructions for preparing the posters will be distributed to authors of accepted poster proposals prior to the conference. Poster presenters will be expected to give a one-minute teaser at a Minute Madness session to encourage visitors to their poster during the poster reception.
Proposals for posters should be one page.
Developer Track
The Developer Track provides a focus for showcasing technical work and exchanging ideas. Presentations are 15-20 minutes and can be informal. Successful developer track presentations include live demonstrations, tours of code repositories, examples of cool features, and unique viewpoints.
Proposals for the developer track should be one page.
Workshops and Tutorials
The first day of Open Repositories 2020 will be dedicated to workshops and tutorials.
Workshops and tutorials generally cover practical issues around repositories and related technologies, tools, and processes. Successful workshops include clear learning outcomes, involve active learning, and are realistic in terms of the number of attendees that can actively participate in the workshop.
Workshops and tutorials can be 90 minutes, 3 hours (half-day), or 6 hours (full day).
Proposals for workshops should be no longer than 2 pages.
Templates
The OR2020 proposal templates help you prepare an effective submission. Please select the submission type below to download the templates. Templates are available in Microsoft Word, Open Document Format and Plain Text. Submission in PDF format is preferred.
Submission System
The system will be open for submissions by the end of November, and the link will be on the conference website (https://or2020.sun.ac.za/).
Review Process
All submissions will be peer reviewed and evaluated according to the criteria outlined in the call for proposals, including quality of content, significance, originality, and thematic fit. The program committee makes the final decisions on inclusion in the conference. If you would like to volunteer to be a reviewer, please contact the program committee below.
Also, please note that the program committee may accept a submission with the requirement that it move to another format (a presentation to a poster, for example). In such cases, submitters will have the opportunity to make a decision on whether to accept or decline such a move.
Code of Conduct
The OR2020 Code of Conduct is available at https://or2020.sun.ac.za/code-of-conduct/. We expect submitters to hold to the Code of Conduct in their proposals, presentations, and conduct at the conference.
Fellowship Programme
OR2020 will again run a Fellowship Programme, which will enable us to provide support for a small number of full registered places (including the poster reception and conference dinner) for the conference in Stellenbosch. The programme is open to librarians, repository managers, developers and researchers in digital libraries and related fields. Applicants submitting a proposal for the conference will be given priority consideration for funding, and preference will be given to applicants from the African continent. Full details and an application form will shortly be available on the conference website.
Key Dates
- 13 January 2020: Deadline for submissions
- 20 January 2020: Deadline for Fellowship Programme applications
- 10 February 2020: Submitters notified of acceptance of workshop proposals
- 10 February 2020: Registration opens
- 17 February 2020: Fellowship Programme winners notified
- 9 March 2020: Submitters notified of acceptance of full presentation, 24×7, poster and developer track proposals
- 20 April 2019: Close of Early Bird registration
- 1-4 June 2020: OR2020 conference
Program Co-Chairs
- Iryna Kuchma, EIFL
- Lazarus Matizirofa, University of Pretoria
- Dr Daisy Selematsela, University of Johannesburg
Contact: or19-program-chairs@googlegroups.com
Local Hosts
Website and Social Media
 Title: Reviving an Old and Valuable Collection of Microscope Slides Through the Use of Citizen Science
Title: Reviving an Old and Valuable Collection of Microscope Slides Through the Use of Citizen Science Title: Efficient Stratified Sampling Graphing Method for Mass Data
Title: Efficient Stratified Sampling Graphing Method for Mass Data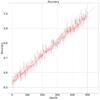 Title: A Comprehensive Video Dataset for Multi-Modal Recognition Systems
Title: A Comprehensive Video Dataset for Multi-Modal Recognition Systems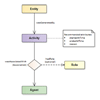 Title: Proper Attribution for Curation and Maintenance of Research Collections: Metadata Recommendations of the RDA/TDWG Working Group
Title: Proper Attribution for Curation and Maintenance of Research Collections: Metadata Recommendations of the RDA/TDWG Working Group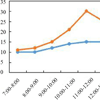 Title: Intelligent Electronic Management of Library by Radio Frequency Identification Technology
Title: Intelligent Electronic Management of Library by Radio Frequency Identification Technology Title: The History and Future of Data Citation in Practice
Title: The History and Future of Data Citation in Practice








 This post was written by Rebecca Lawrence, Managing Director of F1000. She was a
This post was written by Rebecca Lawrence, Managing Director of F1000. She was a