|
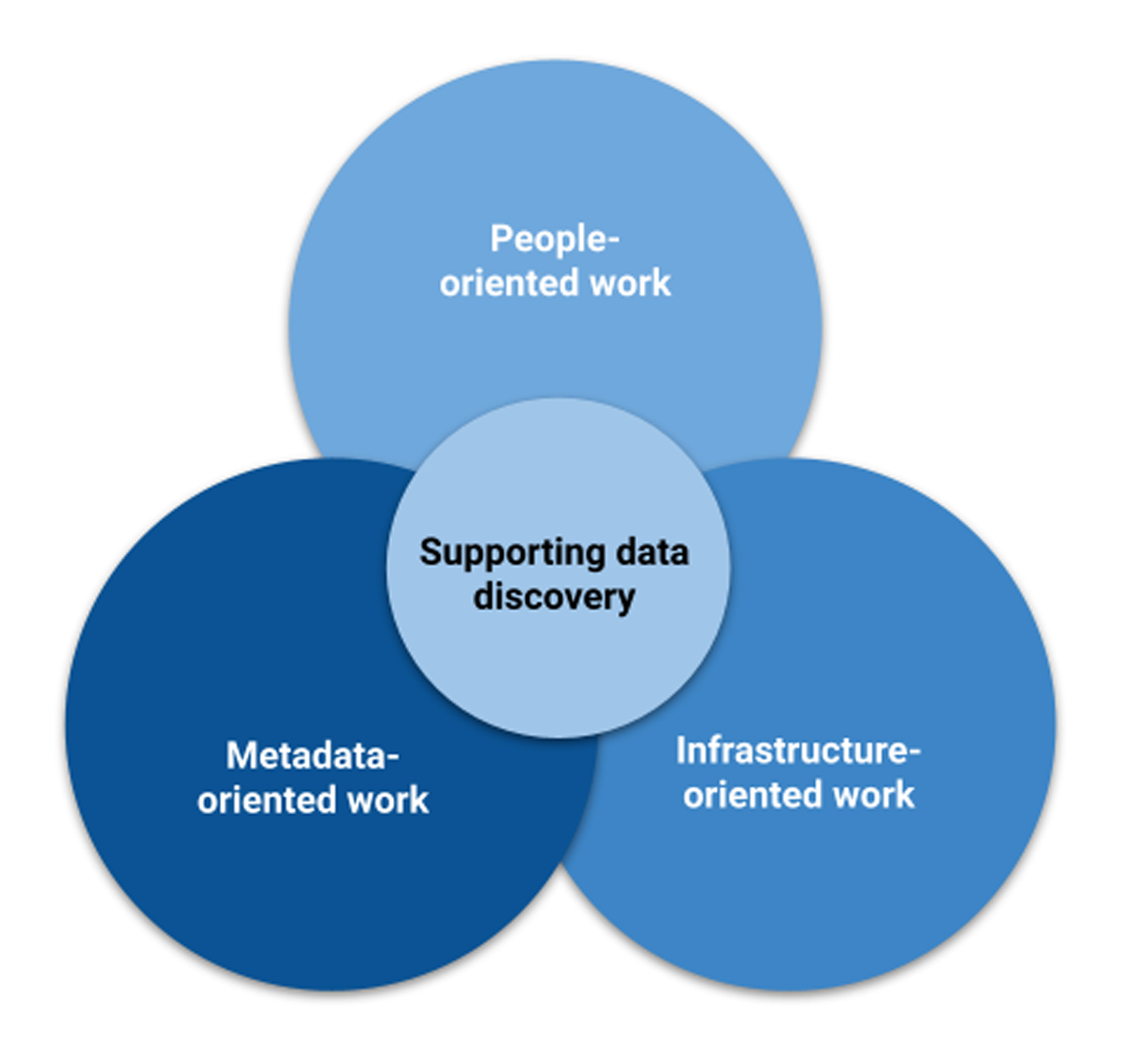
 Title: A Data-Driven Approach to Monitor and Improve Open and FAIR Research Data in a Federated Research Ecosystem Title: A Data-Driven Approach to Monitor and Improve Open and FAIR Research Data in a Federated Research Ecosystem
Author: Markus Kubin, Mojeeb Rahman Sedeqi, Alexander Schmidt, Astrid Gilein, Tempest Glodowski, Vivien Serve, Gerrit Günther, Nina Leonie Weisweiler, Gabriel Preuß, Oonagh Mannix
URL: http://doi.org/10.5334/dsj-2024-041 |
|
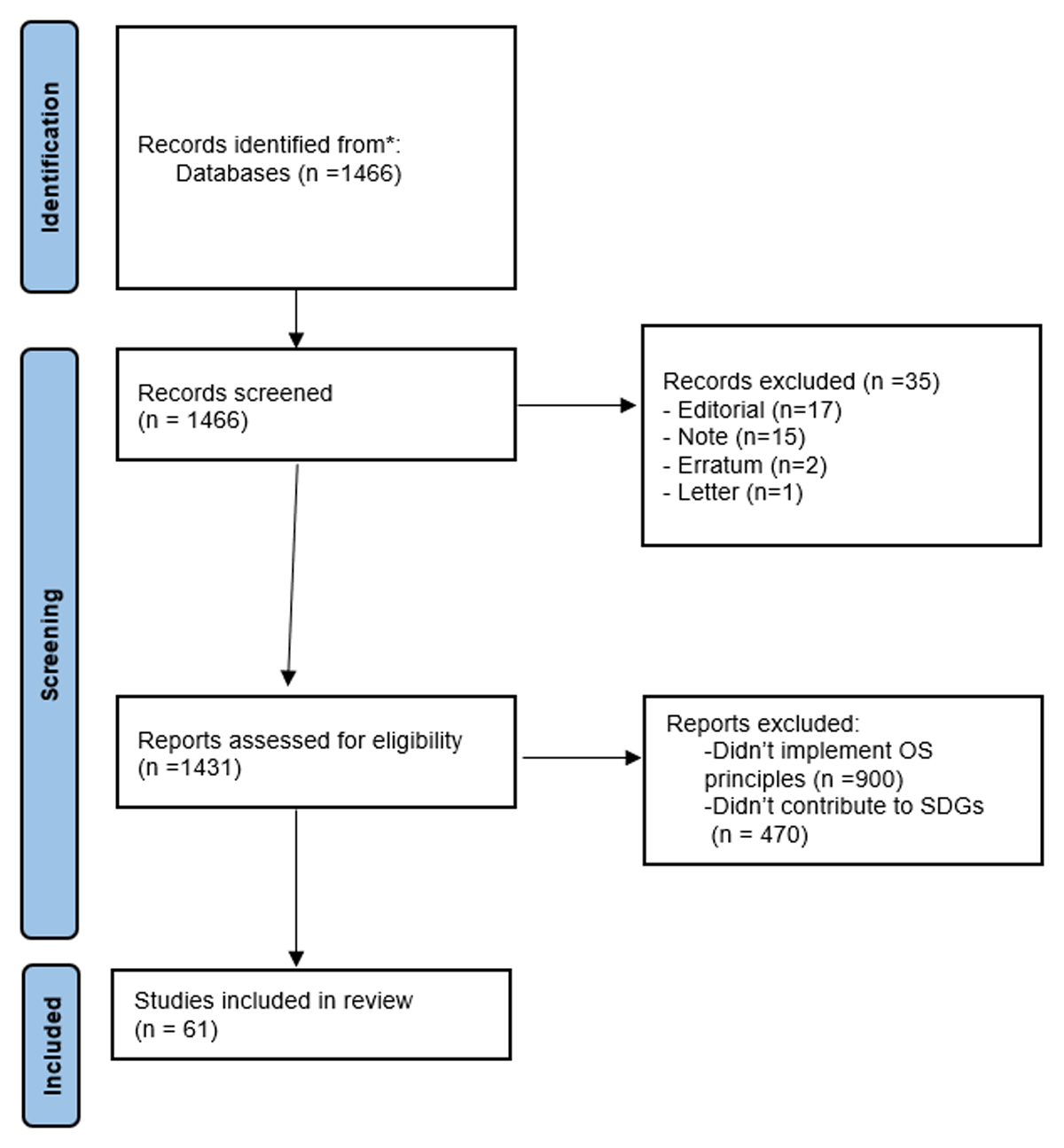
 Title: Enhancing findability and searchability of research data: Metadata conversion and registration in institutional repositories Title: Enhancing findability and searchability of research data: Metadata conversion and registration in institutional repositories
Author: Masahito Nosé, Atsuki Shinbori, Yoshizumi Miyoshi, Tomoaki Hori, Tsukasa Ohira, Junko Hashiba, Chizuko Naoe, Rui Gakiya, Maiko Okamoto, Takeshi Sagara, Takaaki Aoki, Shigeki Matsubara, Ichiro Takahashi, Hidekazu Hayashi, Kazunari Yamada, Yasuyuki Minamiyama, Yoshimasa Tanaka, Shuji Abe, Satoru UeNo, Shun Imajo, Yasuo Saito, Takuya Ashikita, Yuko Hori, Toshiyuki Shimizu, Nanako Okamura, Kaoru Hirano, Lee Bargatze
URL: http://doi.org/10.5334/dsj-2024-040 |
|
 Title: Data on the Margins – Data from LGBTIQ+ Populations in European Social Science Data Archives Title: Data on the Margins – Data from LGBTIQ+ Populations in European Social Science Data Archives
Author: Jonas Recker, Anja Perry
URL: http://doi.org/10.5334/dsj-2024-039 |
|
 Title: The Nansen Legacy Template Generator for Darwin Core and CF-NetCDF Title: The Nansen Legacy Template Generator for Darwin Core and CF-NetCDF
Author:Luke Marsden, Olaf Schneider
URL: http://doi.org/10.5334/dsj-2024-038 |
|
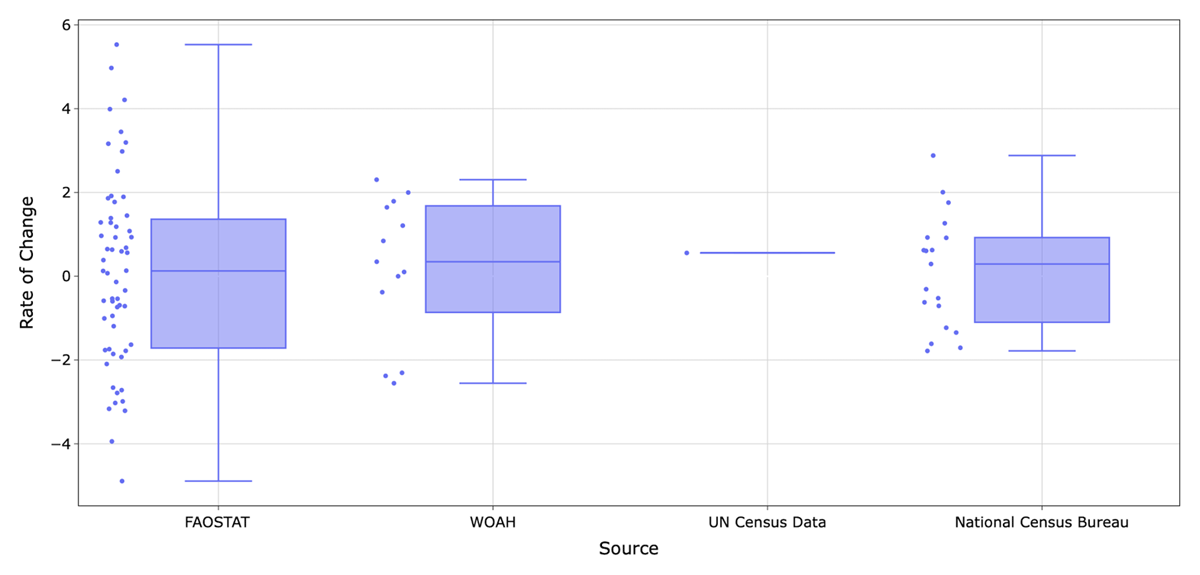
 Title: Earth Science Data Repositories: Implementing the CARE Principles Title: Earth Science Data Repositories: Implementing the CARE Principles
Author:Margaret O’Brien, Ruth Duerr, Riley Taitingfong, Andrew Martinez, Lourdes Vera, Lydia L. Jennings, Robert R. Downs, Erin Antognoli, Talya ten Brink, Nicole B. Halmai, Dominique David-Chavez, Stephanie Russo Carroll, Maui Hudson, Pier Luigi Buttigieg
URL: http://doi.org/10.5334/dsj-2024-037 |
|

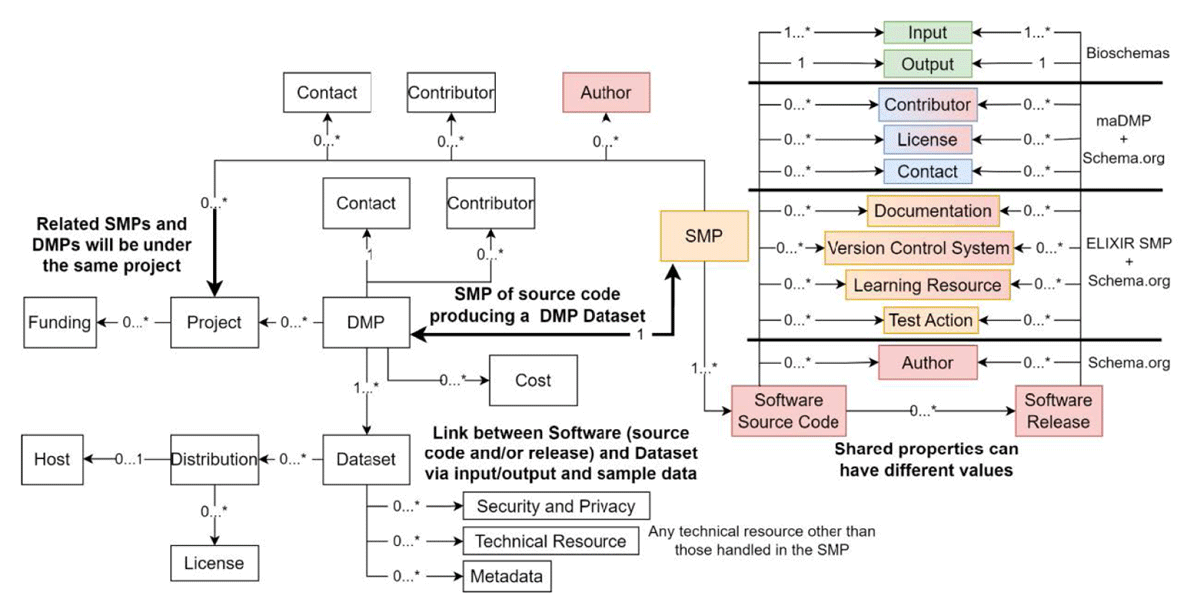
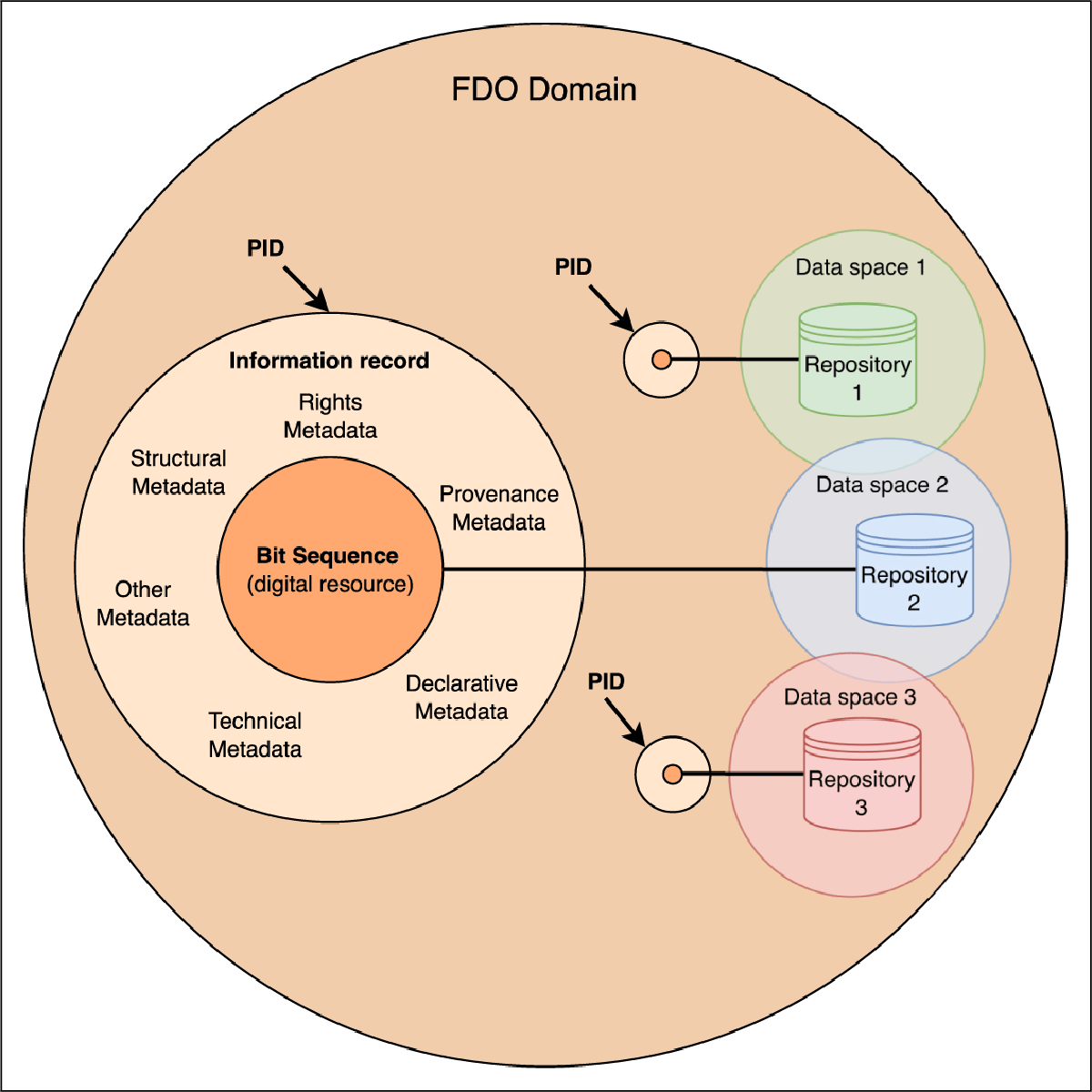 Title: A Comparative Analysis of Modeling Approaches for the Association of FAIR Digital Objects Operations
Title: A Comparative Analysis of Modeling Approaches for the Association of FAIR Digital Objects Operations Title: Evaluating COVID-19 Information and Risk-Averse Behaviours: Insights from Conjoint and Clustering Analyses in the UK, Japan, and Taiwan
Title: Evaluating COVID-19 Information and Risk-Averse Behaviours: Insights from Conjoint and Clustering Analyses in the UK, Japan, and Taiwan